
Machine learning aplicado a la geoestadística para el mejoramiento del control de calidad en la estimación de recursos y reservas
INTRODUCCIÓN
La estimación de recursos minerales es una tarea compleja que requiere la consideración de una gran cantidad de datos geológicos. Las técnicas convencionales de estimación de recursos tienen algunas limitaciones, como el rendimiento deficiente con conjuntos de datos muy heterogéneos, la sobreestimación o subestimación de los recursos, y el procesamiento manual significativo.
Los métodos de aprendizaje automático (ML) ofrecen una posible solución a estas limitaciones. Las técnicas de ML son capaces de aprender y modelar patrones complejos no lineales en grandes conjuntos de datos. Esto les permite superar las limitaciones de las técnicas convencionales y proporcionar estimaciones de recursos más precisas.
En los últimos años, se han desarrollado varios métodos de ML para la estimación de recursos minerales. Estos métodos se han utilizado con éxito para estimar recursos minerales de diversos tipos, incluyendo depósitos de metales, minerales no metálicos y combustibles fósiles.
Los métodos de ML ofrecen una serie de ventajas sobre las técnicas convencionales de estimación de recursos. Son más precisos, pueden aplicarse a conjuntos de datos más heterogéneos, y pueden automatizar el proceso de estimación.
En el futuro, se espera que los métodos de ML desempeñen un papel cada vez más importante en la estimación de recursos minerales. A medida que se desarrollen nuevos métodos de ML y se disponga de más datos de entrenamiento, se espera que las estimaciones de recursos obtenidas mediante métodos de ML sean aún más precisas.
CONCEPTOS BÁSICOS
El aprendizaje automático (ML) ha despertado un creciente interés en los últimos años, especialmente en el campo de las geociencias. ML ha encontrado aplicaciones en diversas áreas geocientíficas, desde la identificación de anomalías geoquímicas hasta la evaluación de recursos minerales. Aunque el uso de técnicas de aprendizaje automático no es nuevo en la industria extractiva, su aplicación ha aumentado en la última década debido a los resultados prometedores que ofrecen en la resolución de problemas complejos.
DEFINICIÓN DE MACHINE LEARNING (ML)
El ML se define como el estudio y la aplicación de algoritmos informáticos que permiten crear sistemas inteligentes capaces de mejorar automáticamente a partir de los datos, sin necesidad de programación explícita. Se clasifica como un subcampo de la inteligencia artificial (IA), que se enfoca en la creación de máquinas inteligentes.
En la práctica, existen diferentes clases de modelos de ML, como el aprendizaje supervisado, no supervisado y por refuerzo. Cada uno de estos enfoques se aplica según la naturaleza del problema que se intenta resolver, utilizando algoritmos de aprendizaje correspondientes.
ETAPAS PARA LA IMPLEMENTACIÓN DE ML
El proceso de implementación del ML sigue diversas etapas. En primer lugar, se define el problema y se adquieren los conocimientos necesarios para obtener los datos relevantes. Luego, se recopilan los datos y se lleva a cabo su preparación, preprocesamiento y transformación. La selección de características implica la elección de parámetros o variables que contribuyan más en la predicción de la variable o resultado de interés. Los datos se dividen en conjuntos de entrenamiento, validación y pruebas, generalmente en una proporción predeterminada, para evaluar el desempeño del modelo.
Figura 1: Etapas para la implementación de ML.
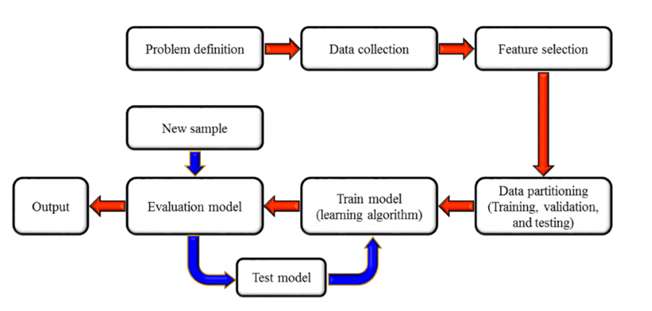
En términos de aplicaciones en la estimación de recursos minerales, se han empleado técnicas de ML como las redes neuronales artificiales (ANN), máquinas de vectores de soporte (SVM), bosques aleatorios (RF), procesos gaussianos (GP) y conjuntos de teorías difusas. Estos modelos han demostrado éxito en la evaluación de diversos yacimientos minerales, incluyendo piedra caliza, oro y cobre.
Figura 2: Técnicas de aprendizaje automático y sus correspondientes algoritmos.
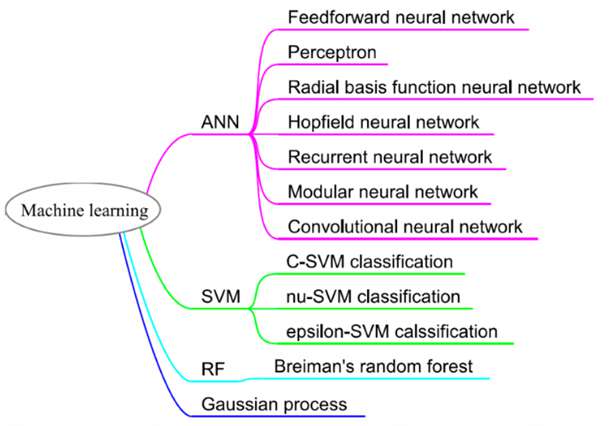
TÉCNICAS DE MACHINE LEARNING
RED NEURONAL ARTIFICIAL (ANN)
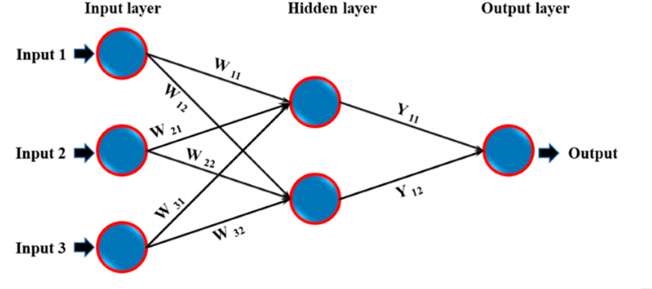
Una Red Neuronal Artificial (ANN, por sus siglas en inglés) es un tipo de red computacional que intenta imitar las operaciones del cerebro humano de manera simplificada. Consiste en capas de nodos interconectados que representan las neuronas. Las capas se dividen en capa de entrada (Input layer), que recibe los datos sin procesar; capas ocultas (hiddenlayer), que procesan los datos; y capa de salida (outputlaye), que produce los datos procesados. La estructura y topología de una ANN se determina por el número de capas y neuronas en cada capa.
Figura 3: Arquitectura ANN simplificada con una sola capa oculta.
En geociencias, se han utilizado diferentes tipos de ANN, como las redes de perceptrón multicapa (MLP), función de base radial (RBF), redes neuronales de regresión general (GRNN), redes neuronales probabilísticas (PNN), mapas autoorganizativos de Kohonen (SOM), modelos de mezcla gaussiana (GMM) y modelos de densidad mixta (MDN), y a su vez, estos modelos se han aplicado en la estimación de la distribución de recursos minerales, clasificación de yacimientos minerales y predicción de la ley del mineral, entre otros.
Las ANN tienen la capacidad de manejar grandes volúmenes de datos complejos, imprecisos y difusos, y ofrecer respuestas rápidas y adecuadas. Han demostrado ser una alternativa robusta a los métodos geoestadísticos para la evaluación de recursos y reservas minerales. Además, se ha explorado la inclusión de atributos geológicos relevantes, como la litología y la alteración, como variables de entrada en los modelos de ANN.
Figura 4: Propuesta de modelo ANN.
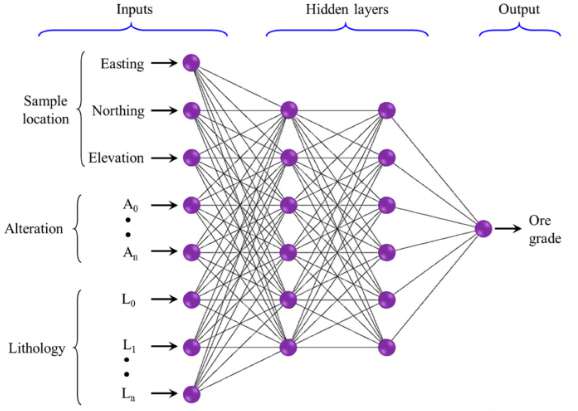
En algunos casos, se han utilizado algoritmos híbridos que combinan redes neuronales con técnicas difusas para cuantificar las incertidumbres en la evaluación de parámetros de inventario mineral. También se han aplicado otros tipos de ANN, como redes neuronales recurrentes (RNN), y se han modelado incertidumbres difusas asociadas a datos geológicos.
SUPPORTVECTORMACHINES (SVM)
Las Máquinas de Vectores de Soporte (SVM) son modelos de aprendizaje automático que se utilizan para la clasificación, regresión y detección de valores atípicos. Estos modelos construyen un hiperplano en un espacio de características de alta dimensión para separar diferentes clases mediante un mapeo lineal. Utilizando ejemplos de entrenamiento pertenecientes a diferentes categorías, un modelo SVM establece una línea de separación en el espacio y luego mapea nuevos ejemplos en ese mismo espacio para predecir su categoría.
Las SVM se están utilizando cada vez más en aplicaciones de exploración de minerales. Por ejemplo, se han empleado para la prospección de minerales, la creación de mapas de zonas mineralizadas, la modelación de inclusiones fluidas, la ubicación de perforaciones de exploración, la separación de zonas de alteración y la caracterización de depósitos de pizarra. También se han utilizado para la estimación de recursos minerales, como en el caso de la estimación del grado de un depósito de mineral de hierro.
Además, las SVM se han mostrado eficientes en la estimación de yacimientos placer, que a menudo tienen pocos datos de muestreo, lo que complica el proceso de estimación. Al combinar muestras adyacentes y utilizar técnicas como la regresión de vectores de soporte, se ha logrado mejorar la precisión de la estimación en comparación con métodos convencionales como la kriging.
En casos donde faltan datos o hay muestras incompletas debido a núcleos de perforación no recuperados, se han propuesto enfoques como el uso de algoritmos basados en Máquinas de Vectores de Relevancia (RVM) o combinaciones de algoritmos que utilizan la distancia cuadrada esperada (ESD) para determinar los valores faltantes y realizar la estimación.
RANDOMFOREST (RF)
Random Forest es una técnica de aprendizaje de conjunto que utiliza una colección de árboles de decisión. En la clasificación, cada árbol produce una clase como salida, y la clase con más votos se convierte en la predicción del modelo. En la regresión, se utiliza la media de las predicciones de los árboles como resultado final. Los árboles de decisión se construyen utilizando una técnica llamada "bootstrapping", donde las muestras se extraen del conjunto de datos de entrenamiento con reemplazo. Esto significa que una muestra puede ser seleccionada varias veces y otras pueden no ser seleccionadas en absoluto. La idea detrás de esto es crear una diversidad de modelos para mejorar la precisión del conjunto.
Random Forest tiene varias ventajas. Es capaz de manejar grandes conjuntos de datos de manera eficiente, puede detectar valores atípicos y ruido, y produce estimaciones de error de generalización internas. Además, es computacionalmente más económico que otros métodos de conjunto, como el "bagging" o el "boosting".
Random Forest se aplica en una amplia gama de áreas, como clasificación de la cubierta terrestre, modelado de aguas subterráneas y prospectividad de minerales. En la estimación de la ley de yacimientos minerales, se ha utilizado con éxito para evaluar los grados de pórfido de cobre, clasificar muestras de mineral de hierro y determinar la mineralización prospectiva de plomo, zinc y plata.
ALGORITMOS EMERGENTES E HÍBRIDOS
Existen otras técnicas de aprendizaje automático que también se aplican en la estimación de recursos minerales, aunque son menos conocidas que las mencionadas anteriormente. Por ejemplo, los Procesos Gaussianos son utilizados en geociencia, en la detección de anomalías forjadas o químicas y en la prospección minera. Se ha aplicado en la estimación del grado mineral de un yacimiento en un caso, donde los resultados fueron mejores cuando se procesaron con estandarización simétrica y anisotrópico kernel exponencial.
Recientemente, los investigadores han estado explorando el potencial de la combinación de técnicas de aprendizaje automático con otras técnicas sofisticadas de cómputo blando. Por ejemplo, se ha utilizado el autoadaptativo basado en aprendizaje de partículas de optimización y soporte vector de regresión (SLPSO-SVR) para la estimación de la calidad de los yacimientos de cobre. También se ha utilizado una combinación de redes neuronales multicapa y algoritmos genéticos para predecir las leyes de oro y plata en un antiguo depósito.
Además, se han explorado nuevas técnicas de visión por computadora integradas con aprendizaje automático para la clasificación y predicción del grado de los recursos minerales. En general, hay una amplia gama de técnicas emergentes de aprendizaje automático que están siendo investigadas actualmente en la estimación de recursos minerales. La combinación de estas técnicas con métodos sofisticados de cómputo blando tiene el potencial de producir una precisión mejorada en la estimación de recursos mineralógicos
CONCLUSIONES
La estimación de los recursos minerales es una tarea desafiante debido a la gran incertidumbre que existe en las formaciones geológicas. Los resultados de estas estimaciones son cruciales para las operaciones mineras, ya que determinan la clasificación del recurso mineral y su viabilidad económica. Por lo tanto, es fundamental elegir un método de estimación adecuado para obtener resultados precisos.
Aunque los modelos de aprendizaje automático tienen un gran potencial en la estimación de recursos, también tienen ciertas limitaciones, como el sobreajuste y el tiempo computacional más largo. Sin embargo, estas limitaciones pueden abordarse mediante la combinación de diferentes modelos de aprendizaje automático y algoritmos de aprendizaje profundo.
También, se ha propuesto que los modelos de aprendizaje automático pueden complementar o integrarse con los métodos de estimación tradicionales para mejorar los resultados. Al utilizar modelos preentrenados existentes, el proceso de implementación se vuelve más rápido, fácil y accesible para los profesionales de la minería.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis