Machine Learning Aplicada la predicción de targets de exploración
Targets de Exploración
Los targets de exploración incluye conceptos como modelos genéticos y de depósitos , conceptos relacionados con la geofísica , análisis espacial , la economía mineral , la probabilidad , mediante estos conceptos lograr un resultado empresarial.
Los targets de exploración es una disciplina científica de alto nivel por derecho propio, siendo la fase conceptual crítica en la predicción semi-cuantitativa de la probabilidad de ocurrencia de minerales que lleva a decisiones sobre la selección de áreas. Si se hace de manera deficiente, no importa cuán eficientes y efectivas sean las etapas siguientes de detección de la exploración el proceso en su conjunto podría estar condenado al fracaso. La calidad de los "Targets de Exploración" es la base sobre la cual se construye toda la estrategia de exploración, y una elección inadecuada de áreas objetivo puede resultar en la asignación de recursos valiosos a áreas que tienen una probabilidad mucho menor de albergar depósitos minerales rentables. En última instancia, la etapa de predicción y selección de objetivos es crucial para el éxito económico y técnico de cualquier proyecto de exploración mineral.
Mediante los avances del Machine Learning nos proporcionan algoritmos mas complejos y eficientes para procesar los datos . Uno de los mayores retos en la geología de explotación es aprovechar al máximo de las cantidades cada vez mayores de datos digitales que se obtienen ahora .
Desafíos y Consideraciones en la Aplicación de Algoritmos de Aprendizaje Automático en la Exploración de Minerales
Variedad de algoritmos de aprendizaje automático: Existen numerosos algoritmos de aprendizaje automático disponibles, algunos de los cuales se han utilizado en la exploración durante más de dos décadas. Sin embargo, su aplicación en la industria minera ha sido recibida con cierta aprensión debido a la falta de transparencia en algunos enfoques que se consideran "cajas negras", como las redes neuronales de aprendizaje profundo.
Transparencia y confianza: La falta de transparencia en algunos métodos, como las redes neuronales de aprendizaje profundo, ha generado preocupaciones en la industria minera. Esto se debe a que no es posible comprender la lógica detrás de las decisiones o conclusiones que se obtienen de estos métodos. Para aumentar la confianza de los responsables de tomar decisiones presupuestarias en la exploración, se recomienda utilizar métodos más transparentes en paralelo, como el "weight of evidence" o métodos de aprendizaje automático que proporcionen información cualitativa sobre el peso relativo de las decisiones (llamados "métodos de caja gris").
Variabilidad en técnicas de aprendizaje automático: Existe una amplia gama de capacidades y eficiencia entre las diversas técnicas de aprendizaje automático. Esta variabilidad aumenta cuando se combinan técnicas o se ajustan los parámetros del algoritmo para lograr un resultado equilibrado.
Selección de algoritmo apropiado: Cada problema tiene un algoritmo óptimo para resolverlo, por lo que es necesario seleccionar cuidadosamente el enfoque de aprendizaje automático adecuado para obtener los mejores resultados posibles.
Medición de la eficacia: Para demostrar que los algoritmos son superiores a las predicciones aleatorias o las predicciones de geólogos utilizando métodos tradicionales, es necesario cuantificar cuán bien pueden predecir si un bloque o nodo dado es mineral o desperdicio. Se utilizan términos como "precisión" y "recall" para medir la capacidad del algoritmo para limitar la cantidad de pozos de perforación desperdiciados y cuantificar el número de cuerpos minerales que se pueden perder al predecir incorrectamente que son desperdicio.
Trade-off entre precisión y recall: La selección de un algoritmo y sus parámetros tiende a favorecer ya sea la precisión o el recall. Esto crea un equilibrio entre los extremos no deseados de perder cuerpos minerales o desperdiciar perforaciones.
Herramientas de medición adicionales: Para evaluar la eficacia de las predicciones, se pueden utilizar herramientas como el puntaje F o análisis y gráficos de Características de Operación del Receptor (ROC). Estos análisis se realizan en un conjunto de prueba.
Desafíos específicos de la exploración de minerales: Se señala que la aplicación no supervisada de algoritmos poderosos a la exploración puede generar resultados engañosos. Algunas técnicas de aprendizaje automático han demostrado ser prometedoras en otros campos, pero aún no han abordado adecuadamente los problemas específicos de los datos de exploración mineral.
Prerrequisitos necesarios: Se enfatiza la necesidad de cumplir con ciertos prerrequisitos para garantizar que el proceso esté bien controlado y que los resultados no sean engañosos en el contexto de la exploración de minerales.
FLUJO DE TRABAJO PROPUESTO PARA APLICAR EL APRENDIZAJE AUTOMATICO A TARGETS DE EXPLORACION
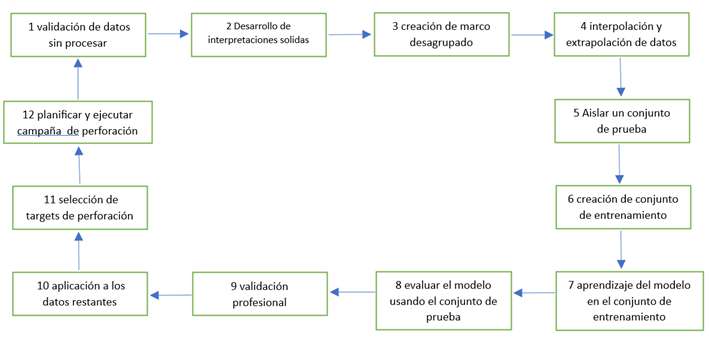
1. La detección de errores en los datos antes de cualquier trabajo garantizara que se eviten resultados espurios. Inconsistencias como la diferencia en unidades serán perjudiciales para el resultado final . En la mayoría de los casos es mejor ignorar o descartar datos poco fiables o intranscendentes
2. Se crea una interpretación sólida de los dominios geológicos, estructurales, metamórficos y geoquímicos regionales y locales mediante la recopilación de datos de campo y herramientas geofísicas. Esto proporciona un marco confiable para limitar la interpolación y extrapolación de datos en el espacio tridimensional.
3. Para que los algoritmos puedan identificar los objetivos más prometedores, se necesita un sistema en el que los datos residan en el espacio tridimensional. Esto incluye ubicaciones con datos y lugares por explorar. La distancia entre estos lugares debe ser idealmente del tamaño de un objetivo de perforación
4. Es importante evitar la entrada de datos erróneos en el proceso. Se requieren herramientas geostadísticas y de inversión geofísica para redistribuir adecuadamente los datos disponibles más allá de su ubicación inicial, respetando las fronteras definidas en el paso 2.
5. Se reserva una parte del conjunto de datos declustrado para probar la tasa de éxito y la posibilidad de sobreajuste del algoritmo de aprendizaje automático. Debe capturar aspectos de los tipos principales de litología, alteración, geofísica, geoquímica y mineralización.
6. Se crea un segundo subconjunto de datos en el que se entrenará el algoritmo seleccionado para clasificar bloques entre resultados positivos (mineral) y negativos (desperdicio). Debe ser representativo de los datos en su totalidad y equilibrado en ejemplos positivos y negativos.
7. Se alimentan los datos en el algoritmo de aprendizaje automático seleccionado y se optimiza la clasificación de bloques de mineral y desperdicio.
8. Se comparan las predicciones del modelo con los datos de prueba para evaluar su rendimiento. Comparar las predicciones con los datos de entrenamiento no es una métrica confiable y puede llevar al sobreajuste del modelo.
9. Un profesional experimentado en exploración revisa y valida las predicciones para identificar problemas que no concuerden con la realidad, como patrones relacionados con la generación de perforaciones o distribuciones espaciales sesgadas.
10. Una vez optimizado y validado, el modelo se aplica al resto del conjunto de datos.
11. Se seleccionan objetivos de perforación finales según su probabilidad de éxito y se evalúan según los objetivos de la campaña.
12. Se planifica y ejecuta la campaña de perforación siguiendo las pautas de un profesional experimentado en exploración, similar a la forma en que se abordan las anomalías geofísicas o geoquímicas. Los datos obtenidos aquí incluso fallidos ayudaran a mejorar las capacidades predictivas del modelo por lo que es necesario repetir el proceso al paso 1
OTRAS APLICACIONES DE ML EN TARGETS DE EXPLORACION
Una aplicación del Machine Learning es la identificación de anomalías desconocidas mediante un conjunto de datos . Esto se puede desarrollar mediante el aprendizaje automático supervisado para entrenar al algoritmo sobre anomalías conocidas de un subconjunto de datos y luego usar este algoritmo entrenado para identificar anomalías desconocidas.
En un articulo de Craig Williams menciona “Que la razón por la que un algoritmo entrenado funciona bien para identificar una nueva anomalía se debe a la capacidad única de algoritmos de aprendizaje automático para comparar múltiples capas de datos simultáneamente” . Cuando un ser humano observa estas capas de datos individuales en un SIG, es difícil comparar especialmente mas de dos o tres capas de manera efectiva en un momento dado . Con el algoritmo de aprendizaje automático se puede analizar múltiples atributos y seleccionar los mejores a discriminar eficazmente entre las clases de anomalías.
El potencial de usar ML es que tiene la capacidad de ver mas atributos de datos que un ser humano con el fin de discriminar eficazmente objetivos sutiles en un espacio multidimensional , y además ofrece la posibilidad de la automatización para así explorar grandes bases de datos.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis