Funciones en Base de Datos MySQL
I. BASE DE DATOS
Una base de datos es una recopilación organizada de información o datos estructurados, que normalmente se almacena de forma electrónica en un sistema informático. Normalmente, una base de datos está controlada por un sistema de gestión de bases de datos (DBMS). En conjunto, los datos y el DBMS, junto con las aplicaciones asociadas a ellos, reciben el nombre de sistema de bases de datos, abreviado normalmente a simplemente base de datos.
Los datos de los tipos más comunes de bases de datos en funcionamiento actualmente se suelen utilizar como estructuras de filas y columnas en una serie de tablas para aumentar la eficacia del procesamiento y la consulta de datos. Así, se puede acceder, gestionar, modificar, actualizar, controlar y organizar fácilmente los datos. La mayoría de las bases de datos utilizan un lenguaje de consulta estructurada (SQL) para escribir y consultar datos.
II. LENGUAJE DE CONSULTA ESTRUCTURADA (SQL)
El SQL es un lenguaje de programación que utilizan casi todas las bases de datos relacionales para consultar, manipular y definir los datos, además de para proporcionar control de acceso. El SQL se desarrolló por primera vez en IBM en la década de 1970 con Oracle como uno de los principales contribuyentes, lo que dio lugar a la implementación del estándar ANSI SQL. El SQL ha propiciado muchas ampliaciones de empresas como IBM, Oracle y Microsoft. Aunque el SQL se sigue utilizando mucho hoy en día, están empezando a aparecer nuevos lenguajes de programación.
III. EVOLUCIÓN DE LA BASE DE DATOS
Las bases de datos han evolucionado drásticamente desde su inicio a principios de la década de 1960. Las bases de datos de navegación, como la base de datos jerárquica (que se basaba en un modelo de árbol y permitía una relación de uno a muchos) y la base de datos de red (un modelo más flexible que permitía relaciones múltiples), eran los sistemas originales que se utilizaban para almacenar y manipular datos. Aunque eran sencillos, estos primeros sistemas eran inflexibles. En la década de 1980, se hicieron populares las bases de datos relacionales, seguidas de las bases de datos orientadas a objetos en la década de 1990. Más recientemente, las bases de datos NoSQL surgieron como respuesta al crecimiento de Internet y la necesidad de acelerar la velocidad y el procesamiento de los datos no estructurados. Hoy en día, las bases de datos en la nube y las bases de datos de autogestión están abriendo nuevos horizontes en lo que respecta a la forma en la que se recopilan, se almacenan, se gestionan y se utilizan los datos.

IV. BASES DE DATOS RELACIONALES
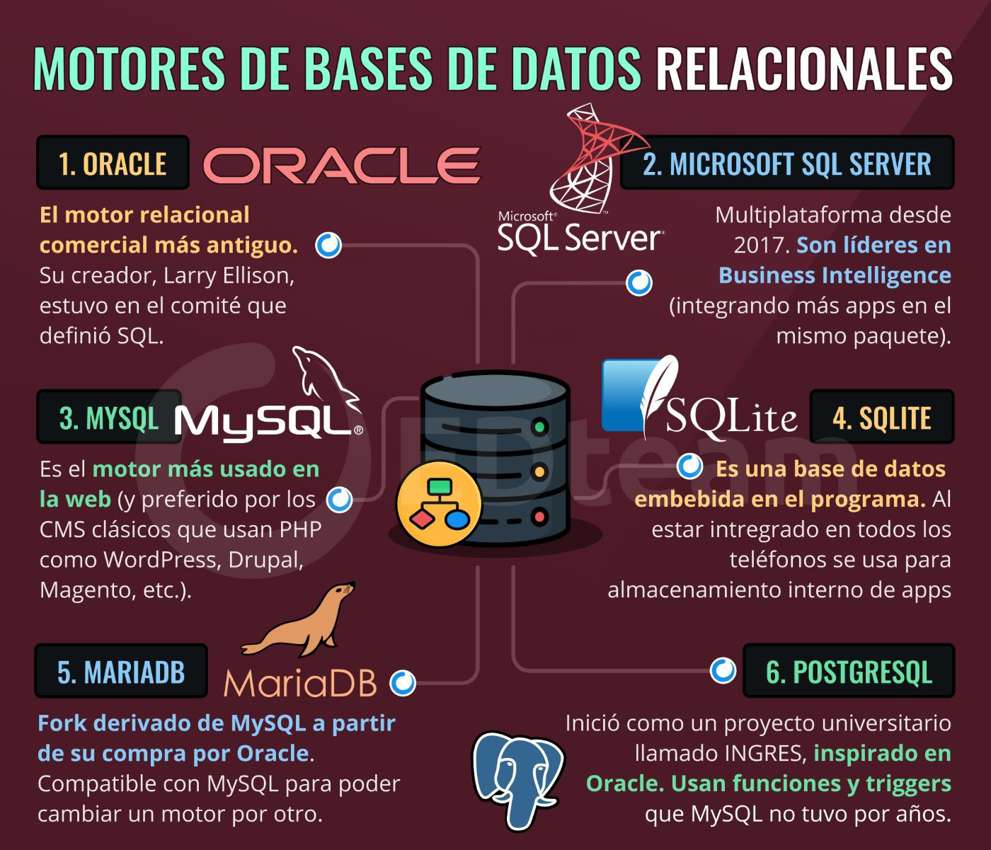
Las bases de datos relacionales se caracterizan por ser una colección ordenada de registros que se organizan en un conjunto de tablas. Estas tablas se relacionan entre sí, dando lugar a una base de datos desde donde se puede acceder a los datos o volver a montarlos de muchas maneras diferentes sin tener que reorganizar las tablas de la base. Para acceder a estos datos, usaremos lo que se conoce como Lenguaje de Consultas Estructuradas, (SQL, Structured Query Language). Con SQL podemos obtener y alterar datos de una forma organizada siempre y cuando tengamos en cuenta cuál es la estructura de la base de datos con la que estamos trabajando. Para ello, utilizaremos los distintos comandos que SQL pone a nuestra disposición.
Las bases de datos relacionales se organizan a través de identificadores. De este modo, cada tabla tiene un identificador único que es el que va a establecer su relación con el resto de tablas. A su vez, estos identificadores hacen que sea más fácil organizar cada una de las tablas por separado. En cuanto a los formatos que se utilizan en este tipo de bases de datos, suele ser el formato tabla, (Un ejemplo serían las hojas de Excel o Access) y los registros se organizarían por filas y columnas.
Los principales sistemas gestores de bases de datos relacionales son: MySQL, MariaDB, SQLite, PostgreSQL, SQL Server y Oracle.
V. BASES DE DATOS NO RELACIONALES
Las bases de datos no relacionales están diseñadas para modelos de datos específicos y que no necesitan ser relacionados con otros modelos. Cada tabla funciona de forma independiente y son mucho más sencillas que los modelos relacionales. Esta sencillez de acceso y de ordenación de la base de datos hace que en el panorama actual estén cobrando más importancia que las relacionales.
Las bases de datos no relacionales pueden tener identificador único, es decir, para identificar cada uno de los registros de la base de datos, pero este identificador no se usará (generalmente) para relacionar unos registros con otros. Como veremos, la información se organiza normalmente mediante documentos y es muy útil cuando no tenemos un esquema exacto de lo que se va a almacenar. Con respecto a los formatos que se utilizan en las bases de datos no relacionales, podríamos decir que el formato más popular es el del documento. En muchos casos, lo que se utiliza es un objeto con una clave y un valor para que el acceso a la información sea pueda realizar de una forma sencilla.
Los principales sistemas gestores de bases de datos no relacionales son: MongoDB, Redis y Cassandra
 .
.
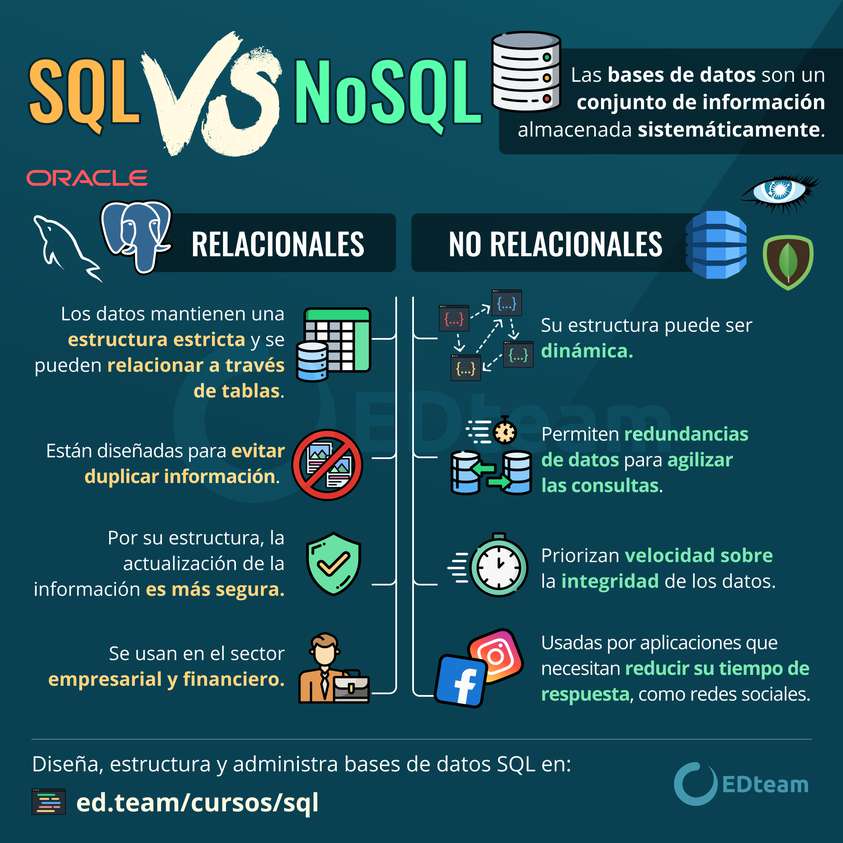
VI. BASE DE DATOS NO RELACIONAL VS RELACIONAL
Las principales diferencias entre las bases de datos relacionales y no relacionales son las siguientes:
- En las bases de datos relacionales la información se organiza de forma estructurada en tablas; en las no relacionales no es así.
- Una base de datos no relacional no usa el lenguaje SQL como lenguaje principal para sus consultas.
- Las bases de datos no relacionales se emplean sobre todo para almacenar datos no estructurados o semiestructurados.
- Una base de datos relacional no cumple con las propiedades ACID con la misma eficacia que una base de datos relacional
- La escalabilidad es mayor en una base de datos no relacional, y también están preparadas para soportar mayor volumen de datos.
- Las bases de datos no relacionales o NoSQL también ofrecen una mayor flexibilidad y escalabilidad horizontal.
- A diferencia de las relacionales, las bases de datos no relacionales todavía no disponen de un lenguaje estandarizado (SQL).
- El soporte de la comunidad es mejor en el caso de las bases no relacionales.
Conoce más sobre la diferencia entre base de datos SQL y No SQL en el siguiente video:
VII. BASE DE DATOS MySQL
MySQL es un sistema de gestión de datos relacionales de código abierto basado en SQL. Se diseñó y se optimizó para las aplicaciones web y puede utilizarse en cualquier plataforma. A medida que surgían nuevos y diferentes requisitos con Internet, MySQL se convirtió en la plataforma preferida por los desarrolladores web y las aplicaciones basadas en web. Dado que está diseñado para procesar millones de consultas y miles de transacciones, MySQL es una elección popular para las empresas de comercio electrónico que necesitan gestionar múltiples transferencias de dinero. La flexibilidad on-demand es la principal función de MySQL.
MySQL es el DBMS que se encuentra detrás de algunos de los sitios web y aplicaciones basadas en web más importantes del mundo, como Airbnb, Uber, LinkedIn, Facebook, Twitter y YouTube.
Conoce más sobre la instalacion y configuracion de MySQL en el siguiente video:
FUNCIONES EN MySQL
Una función almacenada es un conjunto de instrucciones SQL que se almacena asociado a una base de datos. Es un objeto que se crea con la sentencia CREATE FUNCTION y se invoca con la sentencia SELECT o dentro de una expresión. Una función puede tener cero o muchos parámetros de entrada y siempre devuelve un valor, asociado al nombre de la función.
SINTAXIS
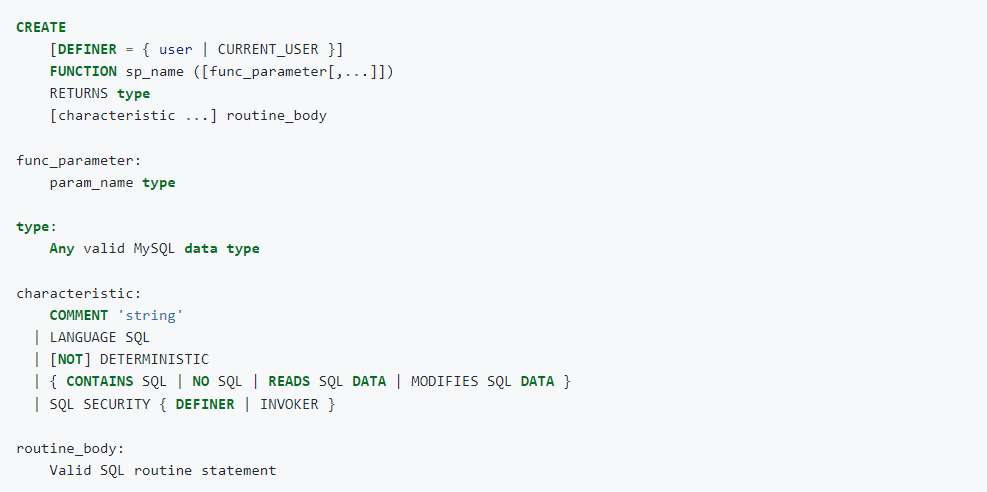
PARÁMETROS DE ENTRADA
En una función todos los parámetros son de entrada, por lo tanto, no será necesario utilizar la palabra reservada IN delante del nombre de los parámetros.
Ejemplo:
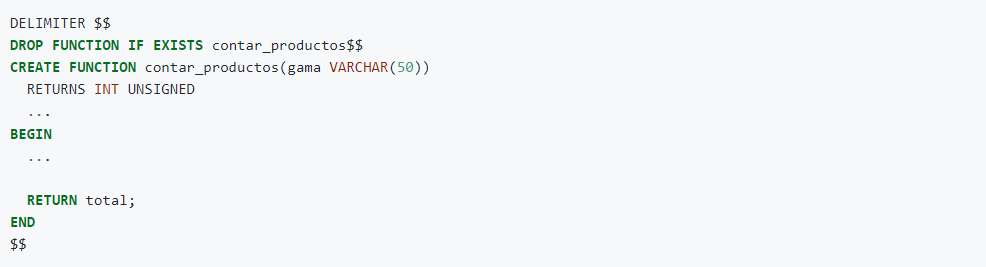
A continuación, se muestra la cabecera de la función contar_productos que tiene un parámetro de entrada llamado gama.

RESULTADO DE SALIDA
Una función siempre devolverá un valor de salida asociado al nombre de la función. En la definición de la cabecera de la función hay que definir el tipo de dato que devuelve con la palabra reservada RETURNS y en el cuerpo de la función debemos incluir la palabra reservada RETURN para devolver el valor de la función.
Ejemplo:
En este ejemplo se muestra una definición incompleta de una función donde se se puede ver el uso de las palabras reservadas RETURNS y RETURN.
CARACTERÍSTICAS DE LA FUNCIÓN
Después de la definición del tipo de dato que devolverá la función con la palabra reservada RETURNS, tenemos que indicar las características de la función. Las opciones disponibles son las siguientes:
- DETERMINISTIC: Indica que la función siempre devuelve el mismo resultado cuando se utilizan los mismos parámetros de entrada.
- NOT DETERMINISTIC: Indica que la función no siempre devuelve el mismo resultado, aunque se utilicen los mismos parámetros de entrada. Esta es la opción que se selecciona por defecto cuando no se indica una característica de forma explícita.
- CONTAINS SQL: Indica que la función contiene sentencias SQL, pero no contiene sentencias de manipulación de datos. Algunos ejemplos de sentencias SQL que pueden aparecer en este caso son operaciones con variables (Ej: SET @x = 1) o uso de funciones de MySQL (Ej: SELECT NOW();) entre otras. Pero en ningún caso aparecerán sentencias de escritura o lectura de datos.
- NO SQL: Indica que la función no contiene sentencias SQL.
- READS SQL DATA: Indica que la función no modifica los datos de la base de datos y que contiene sentencias de lectura de datos, como la sentencia SELECT.
- MODIFIES SQL DATA: Indica que la función sí modifica los datos de la base de datos y que contiene sentencias como INSERT, UPDATE o DELETE.
Conoce más sobre la creacion de funciones en MySQL en el siguiente video:
Para poder crear una función en MySQL es necesario indicar al menos una de estas tres características:
- DETERMINISTIC
- NO SQL
- READS SQL DATA
Si no se indica al menos una de estas características obtendremos el siguiente mensaje de error.

Es posible configurar el valor de la variable global log_bin_trust_function_creators a 1, para indicar a MySQL que queremos eliminar la restricción de indicar alguna de las características anteriores cuando definimos una función almacenada. Esta variable está configurada con el valor 0 por defecto y para poder modificarla es necesario contar con el privilegio SUPER.

En lugar de configurar la variable global en tiempo de ejecución, es posible modificarla en el archivo de configuración de MySQL.
DECLARACIÓN DE VARIABLES LOCALES CON DECLARE
Tanto en los procedimientos como en las funciones es posible declarar variables locales con la palabra reservada DECLARE.
La sintaxis para declarar variables locales con DECLARE es la siguiente.

El ámbito de una variable local será el bloque BEGIN y END del procedimiento o la función donde ha sido declarada.
Una restricción que hay que tener en cuenta a la hora de trabajar con variables locales, es que se deben declarar antes de los cursores y los handlers.
Ejemplo:
En este ejemplo estamos declarando una variable local con el nombre total que es de tipo INT UNSIGNED.

Ejemplos
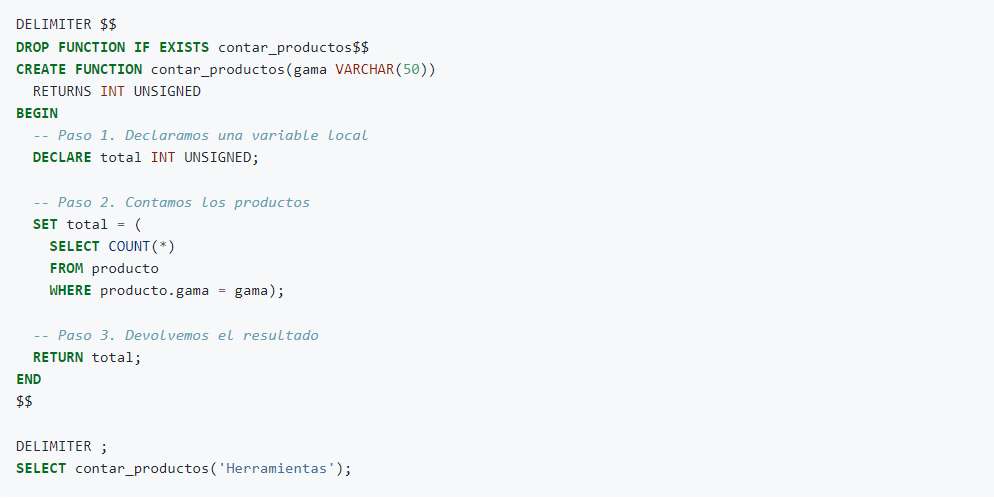
Escriba una función llamada contar_productos que reciba como entrada el nombre de la gama y devuelva el número de productos que existen dentro de esa gama.
VIII. CONCLUSIONES
El uso de funciones en una base de datos MySQL ofrece varias ventajas, que incluyen:
• Reutilización de código: Las funciones permiten encapsular lógica de negocio o cálculos complejos en un solo lugar. Esto facilita la reutilización del código en múltiples consultas o procedimientos almacenados sin necesidad de repetir la misma lógica en varios lugares.
• Mejora del rendimiento: Puedes utilizar funciones para optimizar consultas y cálculos de datos, lo que puede mejorar significativamente el rendimiento de tus aplicaciones. Las funciones pueden ser indexadas, lo que acelera la recuperación de datos y los cálculos.
• Modularidad: Las funciones dividen una tarea en partes más pequeñas y manejables, lo que facilita el mantenimiento y la depuración del código. Esto también facilita la colaboración en equipos de desarrollo, ya que cada miembro puede trabajar en funciones específicas sin afectar otras partes del sistema.
• Abstracción de la lógica de negocio: Al utilizar funciones, puedes ocultar los detalles de implementación de tus cálculos y lógica de negocio. Esto hace que el código sea más fácil de entender y mantener, ya que los desarrolladores pueden centrarse en el "qué" en lugar del "cómo".
• Seguridad: Las funciones pueden utilizarse para controlar el acceso a ciertos datos o realizar validaciones antes de ejecutar una acción. Esto ayuda a garantizar que los datos se manipulen de manera segura y se cumplan los requisitos de seguridad.
• Portabilidad: Si necesitas migrar tu base de datos a otro sistema de gestión de bases de datos (DBMS), las funciones pueden facilitar la transición, ya que solo necesitas reescribir las funciones en el nuevo DBMS en lugar de modificar todas las consultas que las utilizan.
• Facilita la generación de informes: Puedes utilizar funciones para realizar cálculos y transformaciones de datos complejos antes de generar informes. Esto simplifica la generación de informes y garantiza la consistencia de los datos en los resultados.
• Reducción de errores: Al encapsular la lógica en funciones, reduces la posibilidad de cometer errores al escribir consultas o procedimientos almacenados, ya que la lógica se prueba y depura en un solo lugar.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis