
Estimación de recursos minerales utilizando técnicas avanzadas de interpolación espacial basadas en machine learning y geoestadística
INTRODUCCIÓN
Los algoritmos de aprendizaje automático se han desarrollado potencialmente en esta última década y tiene muchas aplicaciones, sobre todo en la automatización de procesos, simplificación, reducción del error humano y ahorro de tiempo. Para la estimación de recursos minerales ya se ha aplicado en varias de sus etapas, incluso, muchos reportes de estimación lo han usado como método de interpolación para declarar sus recursos minerales.
Para empezar, debemos entender la geoestadística como una modelización estadística que adapta las técnicas para imitar las características geológicas, lo cual es útil para poner la geología en valores cuantitativos que nos permite estimar, simular riesgos, cuantificar la incertidumbre, interpolar y simular o analizar riesgos.
¿Cómo usamos un aprendizaje automático para modelar datos espaciales en geoestadística?
Para analizar los datos por machine learning existen muchos métodos. Las técnicas de aprendizaje principal se hacen como supervisado, no supervisado o por reforzamiento. Por ejemplo, la regresión es una forma de aprendizaje supervisado que tiene como objetivo predecir una variable dependiente en función de los datos disponibles. También se debe considerar que luego se entrenará los pesos del algoritmo, se hará un conjunto de pruebas y desarrollo. Por otro lado, el k-means es una técnica no supervisada que separa muestras en "n" grupos con igual varianza y que son las medias de los datos. Finalmente, el aprendizaje por reforzamiento se basa en prueba y error, es decir, se entrena un algoritmo especial para aprendiza por reforzamiento donde en cada "simulación" se le entrena.
En cuanto a la estimación una de las mejores es el kriging simple. En el procedimiento primero se determina el dominio de estimación donde se debe cumplir la estacionariedad de primera y segundo orden, luego de calcula y ajusta el variograma experimental para proporcionar los valores de varianza/covarianza para la estimación.
¿Qué es estacionariedad?
En todo análisis estadístico es importante definir la estacionariedad, y no es más que una representación probabilística que cumple momentos de covarianza independientes de la ubicación. Se desarrolla primero eligiendo el número y tipos de dominios para el modelo numérico, luego se modela los límites de cada dominio, se detecta los tipos de límites y mezcla de modelos, modelan tendencias y se predice con un modelo de tendencias. Se recomienda considerar el modelo u tipo de depósito para definir los dominios más homogéneos.
Función aleatoria estacionaria: Es una representación probabilística con un valor esperado constante y momentos de covarianza independientes de la ubicación. Además, la estacionariedad es determinante para depósitos complejos al aplicar kriging y modelar límites.
Variograma: Es una función de distancia que indica la correlación de dos puntos separados por una distancia. Los tipos de variogramas principalmente usados son:
• Exponenciales: exp(h) = 1 - exp - 3h/a
• Esféricos: sph(h) = 1,5 (h/a) - exp - 3(h/a)
• Gaussiano: gaus(h) = 1 - exp - 3(h/a)
donde a es el rango isotrópico de la función del variograma y h es la distancia de pares muestreados del número total.
Kriging: Los dominios de una función aleatoria estacionaria tienen un variograma experimental calculado. Por esto para estimar mediante kriging se utiliza un modelo de variograma, pues es una estimación lineal basada en una suma de pesos multiplicada por puntos de datos.
Validación de estimaciones
Un método común de validación a modelos predictivos puede ser la técnica de validación cruzada K-fold, donde las estadísticas se calculan en función de cada pliegue. El conjunto de datos se divide y evalúa en k subconjuntos, cada uno tendrá 100/k % de los datos. En cada serie o pliegue, el entrenamiento y la prueba se realizan una vez durante todo el proceso, lo que nos ayuda a evitar el sobreajuste. Para ello, dividimos el conjunto de datos en: entrenamiento, prueba y validación.
Entonces la estimación se ejecuta, en cada serie (pliegue), el entrenamiento y la prueba se realizarían precisamente una vez durante todo este proceso, evitando el sobreajuste. Como sabemos, cuando un modelo se entrena utilizando todos los datos en un solo resumen y brinda la mejor precisión de rendimiento. Resistir esta validación cruzada de k veces nos ayuda a construir un modelo generalizado.
Métodos de estimación con Machine Learning
El primer punto por notar es que al usar machine learning no se requiere el supuesto de estacionariedad. Uno de los métodos es la red neuronal con función de base radial elíptica (FBRE), otro es una combinación de machine learning y kriging, para lo cual se hace una estimación con FBRE y luego se usa el cokriging colocado intrínseco simple u ordinario usando los resultados de RNGBE como datos secundarios en el flujo de trabajo de cokriging intrínseco.
El machine learning aporta en las características no estacionarias a la estimación, mientras que el kriging impone la reproducción y la imparcialidad de los datos. En un estudio de Samantha et al. estimaron los valores de ley mineral usando el FBR y compararon los resultados con redes neuronales de alimentación directa y kriging ordinario convencional, concluyendo que las redes neuronales de retroalimentación proporcionaban mejores resultados que el kriging ordinario.
Predicción geoestadística con una red neuronal
Si solo se trabajase con una función de base radial se genera el problema de la anisotropía, por ello se agrega la "elíptica" para reproducir la anisotropía más efectivamente.
METODOLOGÍA APLICADA
Se cita un ejemplo para un conjunto de datos de la mina Jaguar en Australia Occidental (yacimiento tipo VMS). Para el modelo se utilizó como inputs la litología, alteración, orientación este, norte, altitud, buzamiento y acimut para predecir la pendiente, y las métricas de evaluación del desempeño se midieron con base en el error absoluto medio (MAE), el error cuadrático medio (MSE), error cuadrático medio (RMSE), coeficiente de correlación, R y coeficiente de determinación ( R^2 ).
El objetivo del estudio fue desarrollar un modelo que demuestre los efectos de la ubicación de las muestras y los parámetros geológicos y de perforación para predecir la ley del mineral. Para el caso, se agruparon la litología en cinco categorías como: dolerita, basalto, andesita, sulfuros masivos y sedimentos, para minimizar errores de estimación. En la tabla 1 se muestra una lista de variables de predicción de leyes de mineral no ponderadas y las leyes de mineral correspondientes:
Tabla 1. Lista de variables de entrada no ponderada y ley de mineral de cobre

Luego en la figura 1 se muestra un flujo de trabajo general. Para preparar el modelo de red neuronal artificial, se normalizó los datos de perforación para evitar variabilidad espacial de la ley y los outliers, también para mejorar el aprendizaje del modelo y evitar sobreajustes. Observar que las variables numéricas se han normalizado usando la media y desviación estándar. Los datos se transforman a valores numéricos porque las redes neuronales solo funcionan con números. Además, se usa un método de reserva para dividir los datos como ya se había mencionado: entrenamiento y prueba. Para lo cual se extrae un conjunto de datos para que sirva como caso de prueba.
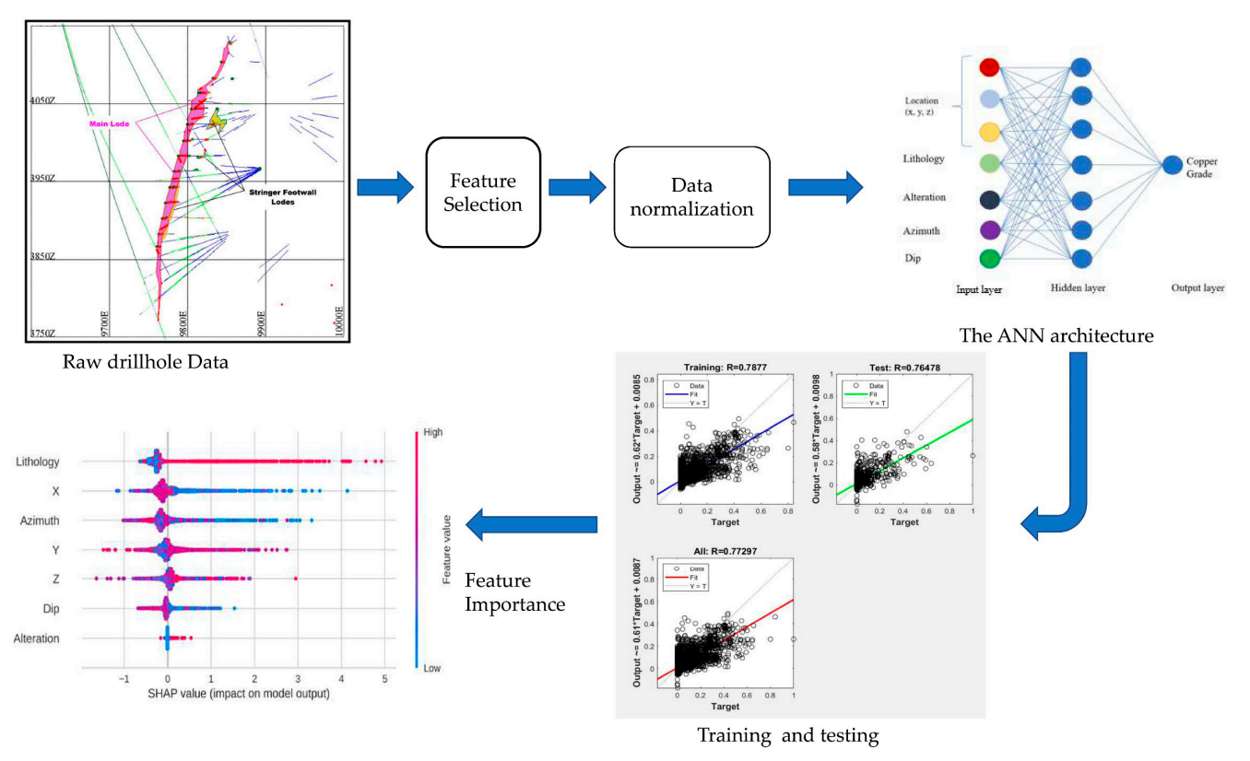
Figura 1. Flujo de trabajo propuesto para estimación
Los datos de entrada y salida se normalizan de cero a uno para complementar el rendimiento de aprendizaje de la ANN, y el método de validación cruzada se usará como datos de prueba. Para este ejemplo se trabajó con el programa de MATLAB usando el método de retro propagación por ser excelente para superar problemas de predicción. Para lo cual se entrena una red neuronal artificial usando un algoritmo de retro propagación de regularización bayesiana.
La regularización bayesiana es una red que minimiza la combinación de errores y pesos al cuadrado para determinar la combinación correcta y lograr un modelo generalizado.
Para medir el rendimiento de predicción de los datos se usaron: el error cuadrático medio, error medio absoluto, raíz del error cuadrático medio, coeficiente de correlación y el coeficiente de determinación. Se usó la regularización bayesiana para entrenar el modelo, lo que evita sobreajuste porque detiene el entrenamiento cuando es necesario. También se trabaja con un histograma de errores para mostrar la distribución de errores del conjunto de datos de entrenamiento y prueba. Finalmente, para comparar con otras técnicas de estimación, se usaron las métricas antes mencionadas.
En la Tabla 4 se muestran los resultados de las metodologías estadísticas utilizadas para predecir la ley del cobre. Los coeficientes de determinación, R^2 para los métodos clásicos (regresor de árboles adicionales, regresor de bosque aleatorio, máquinas de refuerzo de gradiente de luz, regresor vecino K y regresión lineal) fueron 0,575, 0,563, 0,546, 0,541 y 0,123, respectivamente. Los resultados indicaron que estos métodos estadísticos exhibieron coeficientes de correlación moderados, mientras que la regresión lineal tuvo un desempeño deficiente. La regresión lineal mostró el peor desempeño, con la correlación más baja, R^2 de 0,123, lo cual no sorprende dado que la regresión lineal no tiene en cuenta las relaciones no lineales. Dado que la ley del mineral es un componente variable, este método de regresión lineal no puede producir un modelo sólido.
Para el caso de este estudio, se concluye la mejora en estimación usando redes neuronales artificiales sobre otros tipos de métodos clásicos usando siete variables de entrada, sin embargo, uno de los inconvenientes es que no se tiene en cuenta las discontinuidades o fallas geológicas, además las redes neuronales artificiales requieren de una gran cantidad de datos para tener un modelo más preciso de leyes.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis