Machine Learning aplicado al Mapeo Geológico
1. INTRODUCCION
En el inicio de la investigación geológica en el año 1150 a.C., se confeccionaban mapas utilizando técnicas rudimentarias o cualitativas. Con el tiempo, se desarrollaron métodos más detallados que incorporaron modelos de exploración, bases de datos, software y otros elementos, permitiendo la identificación de lugares de interés.
Para crear mapas a través de programas informáticos utilizando programación convencional, se requiere disponer de una base de datos y un programa de análisis. El resultado, es decir, el mapa, se obtiene mediante el procesamiento de la información disponible.
La programación evoluciona, como en el caso del Machine Learning, que emplea una base de datos junto con resultados previos, como datos geológicos, cartográficos y análisis de laboratorio. Estos datos se introducen en una computadora para generar un programa de predicción o modelado predictivo.
La aplicación del machine learning al mapeo geológico representa un avance significativo en la capacidad de los geólogos para comprender y caracterizar el subsuelo de manera precisa, eficiente y basada en datos.
Esta tecnología permite tomar decisiones informadas en la industria minera, la gestión de recursos naturales y la prevención de riesgos geológicos, lo que tiene un impacto positivo en la seguridad, la economía y la sostenibilidad ambiental.
2. MACHINE LEARNING EN LA GEOLOGIA Y SUS VENTAJAS
El Machine Learning es una rama de la inteligencia artificial, emplea algoritmos informáticos para mejorar automáticamente la capacidad predictiva en gran escala . No obstante, aplicar algoritmos matemáticos en el ámbito de las Ciencias de la Tierra se enfrenta a la complejidad de lidiar con numerosas variables difíciles de prever y supervisar.
2.1 MACHINE LEARNING SUPERVISADO:
El aprendizaje supervisado es una rama fundamental del Machine Learning en la que se enseña a un modelo a partir de datos etiquetados. Es decir, se proporciona al modelo un conjunto de datos de entrenamiento que incluye tanto las características de entrada como las salidas deseadas correspondientes. El modelo aprende a hacer predicciones o clasificaciones basándose en esta relación etiquetada entre las entradas y salidas. Durante el proceso de entrenamiento, el modelo se ajusta para minimizar la diferencia entre las predicciones que realiza y las salidas reales, hasta que puede generalizar correctamente para nuevas entradas no vistas.
2.2 MACHINE LEARNING NO SUPERVISADO:
El aprendizaje no supervisado es otra rama importante del Machine Learning en la que se trabaja con datos no etiquetados. Aquí, el modelo se expone únicamente a las características de entrada y no se le proporcionan salidas correspondientes. El objetivo principal es descubrir patrones o estructuras subyacentes en los datos por sí mismo. Esto puede incluir la identificación de grupos similares de datos (clustering), la reducción de la dimensionalidad, la detección de anomalías y otras técnicas que permiten explorar y comprender los datos de una manera no predefinida.
2.3. VENTAJAS DEL MACHINE LEARNING EN LA GEOLOGIA
2.3.1. MEJORA DE LA PRECISIÓN:
El mapeo geológico tradicional se basa en la interpretación manual de datos geológicos, lo que puede llevar a errores humanos y a la subjetividad en la identificación de características geológicas.
El machine learning puede mejorar significativamente la precisión al analizar grandes conjuntos de datos de manera objetiva y consistente.
2.3.2. EFICIENCIA EN EL PROCESAMIENTO DE DATOS:
El mapeo geológico implica el procesamiento de grandes volúmenes de datos, como imágenes de satélite, datos de perforación y registros geofísicos.
El machine learning puede automatizar este proceso, lo que ahorra tiempo y recursos, permitiendo a los geólogos concentrarse en tareas más analíticas y de toma de decisiones.
2.3.3. IDENTIFICACIÓN DE PATRONES OCULTOS:
Los algoritmos de machine learning pueden identificar patrones complejos en los datos geológicos que pueden pasar desapercibidos para los humanos.
Esto puede llevar a la detección de características geológicas importantes o relaciones entre variables que no son evidentes de manera intuitiva.
2.3.4. PREDICCIÓN Y EVALUACIÓN DE RIESGOS:
El machine learning puede utilizarse para predecir la presencia de depósitos minerales, evaluar riesgos geológicos como deslizamientos de tierra o terremotos, y modelar la distribución de recursos naturales.
Estas predicciones son fundamentales para la toma de decisiones en la exploración minera y la planificación de proyectos geológicos.
2.3.5. OPTIMIZACIÓN DE RECURSOS:
El mapeo geológico tradicional puede ser costoso y requerir una gran cantidad de mano de obra.
El machine learning puede optimizar la asignación de recursos al enfocarse en áreas de interés geológico con mayor probabilidad de éxito, lo que reduce los costos y maximiza la eficiencia.
2.3.6. ADAPTACIÓN A CAMBIOS AMBIENTALES:
Dado que el medio ambiente geológico puede cambiar con el tiempo, el machine learning puede monitorear de manera continua y detectar cambios en las condiciones geológicas, lo que es crucial para la gestión ambiental y la mitigación de riesgos.
Conoce un poco más acerca del uso de Machine Learning Supervisado en el Mapeo Geológico en el siguiente video:
3. APLICACION DE ALGORITMOS PARA OPTIMIZAR EL NÚMERO DE CLÚSTERES Y PARÁMETROS DE ENTRENAMIENTO PARA MEJORAR EL RENDIMIENTO DE UN ALGORITMO DE MACHINE LEARNING SUPERVISADO EN EL MAPEO GEOLOGICO
Se consideran cuatro Algoritmos de Machine Learning supervisados tales como Naïve Bayes, k-vecinos más cercanos, bosque aleatorio y máquinas de vectores de soporte. Naïve Bayes utilizado aquí es el método Naïve Bayes Gaussiano
3.1 PREPROCESAMIENTO Y FUENTE DE DATOS
Los conjuntos de datos mencionados en la Tabla 1 se ajustaron para hacer referencia a un sistema de coordenadas común, el NAD83, y se redimensionaron para tener la misma resolución que el conjunto de datos de menor resolución, es decir, 1000 m × 1000 m. Las imágenes espectrales de la zona de interés se obtuvieron a partir de los conjuntos de datos Landsat 4-5 TM disponibles en el USGS.
Estas imágenes se tomaron en octubre de 2011, cuando la cobertura vegetal estacional era menor y no obstruía la calidad de las imágenes. Además, se utilizaron diversas relaciones entre bandas como entradas de características para los conjuntos de datos de calibración, y se detallan en la Tabla 2. Todas estas características de entrada, como la intensidad magnética total, la elevación, la gravedad y las imágenes espectrales, se emplearon para crear una firma digital única para cada tipo de roca utilizando datos de calibración.
Posteriormente, se utilizaron estas firmas para identificar puntos sin etiquetar durante el proceso de clasificación. Los tipos de roca utilizados para asignar etiquetas a los conjuntos de datos de calibración, clasificación y validación se obtuvieron de la Ontario Geological Survey (OGS) y se pueden apreciar en la Figura 1, junto con sus descripciones y la leyenda correspondiente que se muestra en la Tabla 1 (Ontario Geological Survey, 2011).
Figura 1. Mapa de tipos de roca de la Cuenca de Sudbury y sus alrededores (Ontario Geological Survey, 2011).

Tabla 1. Leyenda y descripciones de tipos de roca para la Figura 1. Incluye el porcentaje de cuánto cubre cada tipo de roca del área de estudio. Adaptado de la Encuesta Geológica de Ontario (2011).

3.2 MODELO DE CALBRACIÓN
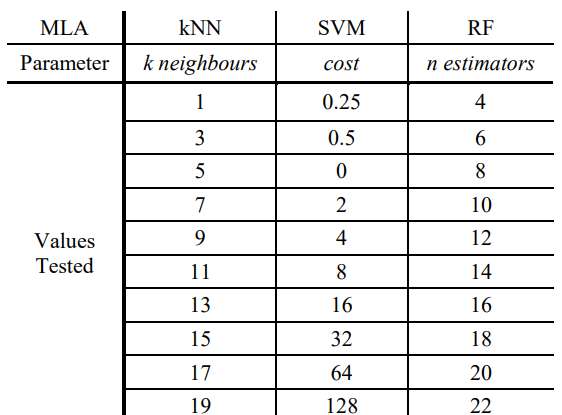
Los parámetros ideales específicos para cada uno de los 4 algoritmos de machine learning supervisados se determinaron mediante una validación cruzada de 10 divisiones realizada en conjuntos de datos de calibración que incluían diversas tamaños de agrupaciones y distribuciones espaciales. Los valores de los parámetros examinados se detallan en la Tabla 2
Estos parámetros óptimos se utilizaron como entradas para la fase de evaluación de predicciones de este estudio.
Los datos de calibración estaban compuestos por agrupaciones (cluster) que representaban consistentemente el 20% de los puntos de datos del área de estudio. Cada uno de los algoritmos de machine learning se ejecutó para un total de 2 agrupaciones o cluster, donde a variaba de 0 a 9.
Este proceso se repitió en tres pruebas distintas para cada uno de los algoritmos de machine learning, para tener en cuenta la aleatoriedad en la selección de las agrupaciones iniciales.
Esta variabilidad puede dar lugar a composiciones de puntos de calibración sustancialmente diferentes debido a las ubicaciones de las agrupaciones y las cantidades desiguales y la distribución no uniforme de cada tipo de roca.
Los resultados de la validación cruzada de cada prueba se promediaron para obtener los resultados finales de la calibración del modelo. Tanto en la fase de calibración como en la evaluación final de predicciones, se asume que el muestreo aleatorio simple utilizado en este estudio es más representativo de las travesías y procedimientos típicos en el mapeo geológico de campo que el muestreo estratificado (Congalton, 1991).
Tabla 2. Parámetros y valores probados para cada Algoritmo de Machine Learning durante la validación cruzada. La validación cruzada tiene como objetivo determinar cuál valor de parámetro ofrece el mejor rendimiento para cada Machine Learning
3.3 EVALUACIÓN DE PREDICCIÓN
Se llevaron a cabo análisis de los resultados de cada Algoritmo de Machine Learning (AML) utilizando tres enfoques:
1. La observación visual de cada clasificación
2. La comparación de la clasificación con visualizaciones que mostraban los datos correctamente e incorrectamente identificados, además de las ubicaciones de los clústeres
3. La evaluación del rendimiento general a través del porcentaje de píxeles correctamente identificados. El propósito principal era determinar cuál Algoritmo de Machine Learning y bajo qué condiciones lograba el mejor rendimiento.
3.4 RESULTADOS
3.4.1 RESULTADOS DE VALIDACION CRUZADA
En la Figura 2 se presentan los resultados obtenidos durante la validación cruzada, la cual se llevó a cabo para determinar los parámetros óptimos que se utilizarían en la evaluación de predicción del estudio.
Los puntos rojos en la figura representan el mejor rendimiento obtenido para cada número de clústeres en cada Algoritmo de Machine Learning.
Las precisiones de la validación cruzada de todos los Algoritmos de Machine Learning muestran tendencias similares entre sí a medida que varía el número de clústeres, con un rendimiento ligeramente mejor en los extremos del rango de clústeres y una disminución en el rendimiento centrada alrededor de 16 a 64 clústeres.
La Tabla 3 resume el rendimiento alcanzado utilizando los parámetros que mejor funcionaron para cada Algoritmo de Machine Learning y los clústeres correspondientes. El rendimiento se mide en términos del porcentaje de píxeles correctamente identificados.
Tabla 3. Precisión para el mejor parámetro de rendimiento para cada Algoritmo de Machine Learning y número de grupos obtenidos de la validación cruzada. El mejor rendimiento entre los grupos con el valor de parámetro correspondiente para cada Algoritmo de Machine Learning y se resalta en rojo.

Los resultados indican un rendimiento deficiente, con la mejor precisión alcanzando un 76%. Esto puede deberse a varios factores, incluida la presencia de una considerable cobertura vegetal que dificulta la clasificación de las rocas (para una aplicación más adecuada del mapeo geológico, se recomienda consultar Cracknell y Reading, (2014). Además, no se ha tenido en cuenta la presencia de cuerpos de agua en el análisis.
Figura 2. Comparación de las precisiones promedio a lo largo de tres pruebas, es decir, con ubicaciones de clústeres de calibración variadas, de la validación cruzada para cada Algoritmo de Machine Learning (AML) en función del número de clústeres y los valores de parámetros a probar según se especifica en la Tabla 2. Los puntos rojos indican el mejor rendimiento y el valor de parámetro que resultó en los valores utilizados en la evaluación de predicción, los cuales se resumen en la Tabla 3.

3.4.2 RESULTADOS DE LA EVALUACIÓN DE PREDICCIÓN DEL ÁREA DE ESTUDIO
La Figura 3 ilustra los resultados de predicción y las distribuciones espaciales de los puntos de datos correctamente identificados en el componente de evaluación de predicción del estudio. Se comparan las predicciones para 1 y 512 grupos.
En las imágenes en color se presentan los resultados de predicción de tipos de rocas por parte del algoritmo de machine learning, mientras que la imagen adyacente muestra los puntos de datos identificados correctamente en gris y los incorrectamente identificados en negro. En ambas imágenes, se pueden ver grupos de puntos de datos con colores claros que representan los grupos.
Para más detalles sobre el mapa de validación y la leyenda, se puede consultar la Figura 1 y la Tabla 2. Estas imágenes muestran que a medida que aumenta el número de grupos de calibración, se vuelven más evidentes las tendencias estructurales y litológicas principales, así como los contactos, y que la identificación correcta de los tipos de rocas mejora con una mayor cantidad de grupos de calibración y su distribución.
Figura 3. Representaciones visuales de las predicciones de tipos de rocas, distribuciones de grupos y puntos de datos identificados correctamente para cada algoritmo de machine learning (AML). Se muestran los resultados para 1 y 512 grupos. La imagen en color muestra las predicciones de tipos de rocas con píxeles de calibración en colores más claros según la leyenda. Junto a ella, se encuentran imágenes de visualización del rendimiento, donde se pueden observar los píxeles de calibración (colores claros según la leyenda), celdas identificadas correctamente (en gris) y celdas identificadas incorrectamente (en negro). Consulte la Figura 2 para ver el mapa completo de tipos de rocas y la Tabla 3 para la leyenda completa

La Figura 4 resume el rendimiento general de cada método de clasificación, demostrando que el rendimiento de cada algoritmo de machine learning generalmente mejora a medida que aumenta el número de grupos de calibración.
En la figura se incluyen líneas de tendencia de regresión en escala logarítmica-lineal, así como valores de R2 para cada algoritmo de machine learning
En general, el algoritmo de Naïve Bayes(NB) muestra el rendimiento más deficiente. Tanto Naïve Bayes (NB) como el vecino más cercano (KN) presentaron un rendimiento similar en relación con la cantidad de grupos de calibración, sin embargo, Naïve Bayes (NB) se ajusta peor a los datos de los cuatro algoritmos de machine learning supervisados.
El bosque aleatorio(RF) produjo los mejores resultados, con la línea de tendencia más pronunciada y un mejor ajuste de los datos.
Figura 4 Rendimiento general (porcentaje de píxeles identificados correctamente) para cada algoritmo de machine learning (AML) en función del número creciente de grupos de calibración.

3.5 ANÁLISIS DE RESULTADOS
- Los resultados de este estudio indican que la técnica utilizada no es confiable para mapear la litología en áreas con vegetación densa y presencia de agua. Se sugieren varias estrategias para mejorar el rendimiento, como aplicar la técnica en áreas con menos vegetación, reducir el peso de las entradas espectrales dependientes y agrupar unidades geológicas con composiciones similares.
- El metodo de Bayes gausiano(NB) no permite ajustar parámetros de entrada ya que la media poblacional y la desviación estándar se determinan automáticamente según la máxima verosimilitud. En contraste, el algoritmo de k-vecinos(KN) más cercanos requiere especificar el número de vecinos (k) como un parámetro de entrada.
- Las máquinas de vectores de soporte (SV) (Cortes y Vapnik, 1995) establecen límites de clasificación como hiperplanos en espacios de alta dimensión. Estos límites se definen por los vectores de soporte, que son puntos de datos de calibración y se colocan de manera óptima para maximizar la distancia entre el límite y los vectores de soporte de las dos clases. La variable que se ajusta en este método es el costo asociado con la clasificación incorrecta de los vectores de soporte, donde costos más altos conducen a límites más complejos.
- El algoritmo de bosque aleatorio (RF) se puede optimizar ajustando el número de árboles de decisión o estimadores. Todos los algoritmos de machine learning mencionados en este estudio se implementan a través del módulo Scikit-learn en Python 2.7 (Pedregosa y Varoquaux, 2011).
- Se discute la importancia de la distribución espacial uniforme de grupos de calibración y se observa que un número bajo de grupos podría funcionar mejor en ciertas situaciones. Además, se señala que el rendimiento mejora a medida que aumenta el número de grupos de calibración durante la evaluación de predicción en todo el área de estudio.
- El Bosque Aleatorio se destaca como el algoritmo de macine learning con el mejor rendimiento, aunque se menciona la posibilidad de sobreajuste en algunos casos.
4. CONCLUSIONES
- La inclusión de datos geofísicos adicionales, como la intensidad magnética total, la elevación digital y la anomalía de gravedad de Bouguer, como características de clasificación, demostró ser valiosa para la evaluación inicial y la interpretación de los tipos de rocas geológicas. Antes de emprender visitas de campo, los geólogos recopilan información geológica previa sobre un sitio para identificar áreas de interés y tendencias estructurales.
- A pesar de que se identificó el bosque aleatorio como el algoritmo de machine learning más efectivo, su rendimiento general aún no es suficiente para sustituir investigaciones de campo adecuadas. No obstante, puede ser una herramienta útil en la planificación de recorridos de campo para mejorar las interpretaciones geológicas durante la fase inicial de estudio.
5. REFERENCIAS BIBLIOGRÁFICAS
1. Mitchell, Tom. Machine Learning. s.l. : McGraw-Hill, 1997.
2. Pizano, L. Machine Learning aplicado a la geología. Lima : INGEMET, 2021.
3. Harvey, A. S. ; Fotopoulos, G.Geological Mapping Using Machine Learning Algorithms.Canada,2016
4. Cortes, C., & Vapnik, V., 1995. Support-vector networks. Machine Learning, 20, pp. 273-297.
5. Pedregosa, F., & Varoquaux, G., 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, pp. 2825-2830.
6. Cracknell, M.J., & Reading, A.M., 2014. Geological mapping using remote sensing data: A comparison of five machine learning algorithms, their response to variations in the spatial distribution of training data and the use of explicit spatial information. Computers & Geosciences, 63, pp. 22-33.
7. Ontario Geological Survey, 2011. 1:250 000 scale bedrock geology of Ontario. Ontario Geological Survey, Miscellaneous Release - Data 126 - Revision 1.
8. Congalton, R.G., 1991. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sensing of Environment, 37(October 1990), pp. 35-46.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis