
La predicción de riesgos geológicos mediante modelos de Machine Learning
INTRODUCCION:
La predicción de riesgos geológicos mediante modelos de machine learning es un enfoque prometedor que puede mejorar nuestra capacidad para prever y mitigar desastres naturales relacionados con fenómenos geológicos, como terremotos, deslizamientos de tierra, erupciones volcánicas y tsunamis. Los modelos de machine learning pueden procesar grandes cantidades de datos geológicos y ambientales para identificar patrones y tendencias que podrían pasar desapercibidos por los seres humanos. Aquí tienes una guía general sobre cómo podría llevarse a cabo este proceso:
RECOPILACION DE DATOS
El primer paso es recolectar una cantidad significativa de datos relevantes. Esto puede incluir datos sísmicos, geodésicos, geológicos, topográficos, climáticos, de sensores remotos y más. Estas fuentes de datos podrían incluir estaciones de monitoreo, satélites, sensores en el terreno y bases de datos históricas.
Supongamos que estamos interesados en predecir la ocurrencia de terremotos en una región específica. En este caso, el proceso de recopilación de datos podría incluir lo siguiente:
• Recopilación de Datos Sísmicos: Necesitas conocer la historia de los terremotos en esa área. Esto implica recopilar información sobre cuándo y dónde ocurrieron terremotos anteriores, así como su magnitud y profundidad. Se recopilan datos sísmicos históricos de la región de interés. Estos datos pueden provenir de estaciones sísmicas locales, registros gubernamentales, bases de datos geofísicas o fuentes confiables similares. Los datos sísmicos incluyen información sobre la magnitud, la profundidad, la ubicación y la fecha de los terremotos pasados.
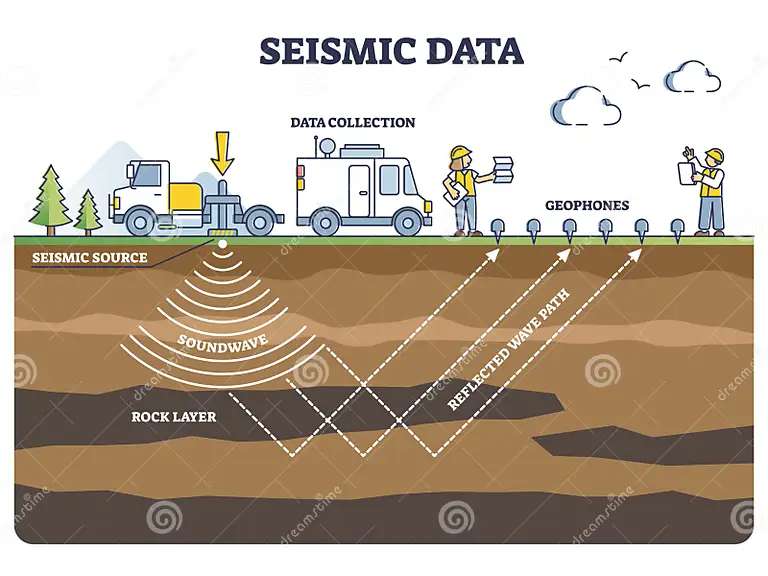
Imagen 01. Método de recolección de datos sísmicos con geofones y esquema de ondas sonoras
• Datos Geológicos: Debes entender cómo es la tierra en esa región. Esto incluye identificar si hay fallas geológicas, que son grietas en la Tierra que pueden causar terremotos, y qué tipo de rocas y suelos hay en el subsuelo. Se recopilan datos geológicos de la región, que incluyen información sobre la estructura de la corteza terrestre, fallas geológicas conocidas, características geológicas locales y la geología subyacente. Estos datos pueden provenir de estudios geológicos, mapas geológicos y expertos en geología local.
• Datos de Topografía y Geografía: Saber cómo es el terreno en la zona es importante. Esto implica conocer la elevación de la tierra, si hay montañas, ríos o lagos cercanos, y cómo se encuentra ubicada la zona respecto a otras regiones geográficas. Se obtienen datos topográficos y geográficos de la zona, que pueden incluir elevaciones, pendientes del terreno, cuerpos de agua cercanos y otros factores que puedan influir en la propagación de ondas sísmicas.
• Datos Climáticos: Los factores climáticos también pueden ser relevantes. Se recopilan datos climáticos relevantes, ya que ciertas condiciones climáticas, como lluvias intensas, pueden aumentar el riesgo de deslizamientos de tierra después de un terremoto. Los datos climáticos pueden provenir de estaciones meteorológicas locales.
• Registros de Actividad Sísmica Actual: Monitorear la actividad sísmica actual es esencial. Se recopila información sobre la actividad sísmica actual en la región mediante el monitoreo en tiempo real de estaciones sísmicas y sensores sísmicos desplegados en la zona.
• Datos Socioeconómicos: También es importante considerar datos socioeconómicos, como la densidad de población, la infraestructura crítica, la ubicación de hospitales y escuelas, ya que estos factores pueden influir en el impacto de un terremoto en la comunidad.
Una vez recopilados todos estos datos, se pueden utilizar para alimentar modelos de machine learning que ayuden a predecir la probabilidad y la severidad de futuros terremotos en la región. Estos modelos analizarán los patrones y las relaciones en los datos para proporcionar alertas tempranas y ayudar en la toma de decisiones en la gestión de riesgos geológicos.
PREPARACION DE DATOS
Los datos recolectados pueden estar en diversos formatos y calidades. Es necesario realizar un preprocesamiento para limpiar, normalizar y transformar los datos en un formato adecuado para el análisis. Esto podría implicar la eliminación de valores atípicos, la corrección de errores y asegurarse de que los datos estén en la misma escala.
A continuación, se presentan ejemplos de técnicas de preparación de datos específicas para el tema de predicción de riesgos geológicos:
• Eliminación de Datos Anómalos: Ejemplo: Si tienes un conjunto de datos de actividad sísmica y encuentras lecturas extremadamente inusuales o no plausibles (por ejemplo, una magnitud de terremoto negativa), puedes eliminar esos datos ya que pueden ser errores en la medición.
• Interpolación de Datos Temporales: Ejemplo: Si tienes datos de sismos registrados a intervalos irregulares de tiempo, puedes realizar una interpolación para tener una serie de tiempo con intervalos regulares, lo que facilita el análisis y la detección de patrones.
Agregación de Datos Geoespaciales: Ejemplo: Si tienes datos de diferentes sensores geológicos distribuidos en una región, puedes agregarlos espacialmente para obtener estadísticas regionales que representen mejor la actividad geológica en esa área.
• Normalización de Datos Geofísicos: Ejemplo: Si estás trabajando con datos geofísicos, como la resistividad eléctrica del suelo, puedes normalizar los valores para tener una escala consistente y facilitar la comparación entre diferentes ubicaciones.
• Creación de Características de Riesgo: Ejemplo: Puedes calcular características de riesgo adicionales, como la densidad de fallas geológicas en una región, la velocidad de movimiento del suelo o la historia de terremotos pasados, que pueden ser relevantes para predecir futuros eventos geológicos.
• Agrupación de Regiones Geográficas: Ejemplo: Si tienes datos de riesgos geológicos para diferentes áreas geográficas, puedes agrupar regiones similares en función de características geológicas compartidas para simplificar el análisis y la predicción.
• Manejo de Series Temporales de Datos Sísmicos: Ejemplo: Para series temporales de datos sísmicos, puedes suavizar o filtrar las lecturas para eliminar ruido y destacar tendencias significativas.
• Selección de Características Geoespaciales: Ejemplo: Si tienes una gran cantidad de características geoespaciales, como datos de elevación, tipos de suelo y temperatura, puedes realizar un análisis de importancia de características para seleccionar las más relevantes para la predicción de riesgos.
• Integración de Datos Meteorológicos: Ejemplo: Puedes combinar datos geológicos con datos meteorológicos, como precipitación y temperatura, para evaluar cómo las condiciones climáticas pueden influir en la actividad geológica, como deslizamientos de tierra después de lluvias intensas.
• Muestreo de Datos para Modelos de Predicción: Ejemplo: Si estás construyendo un modelo de predicción de terremotos y tienes una gran cantidad de datos, puedes realizar un muestreo estratégico para reducir la cantidad de datos, manteniendo la representatividad y reduciendo el tiempo de entrenamiento del modelo.Principio del formulario.
Una mejor explicacion sobre la prepracion de datos:
SELECCIÓN DE CARACTERISTICAS
En este paso, se eligen las características relevantes para el análisis. Algunas características podrían impactar directamente en los riesgos geológicos, como la actividad sísmica previa, la pendiente del terreno, la humedad del suelo, etc.
La selección de características te permite concentrarte en las variables que tienen un impacto significativo en la predicción de deslizamientos de tierra, lo que simplifica el modelo y lo hace más eficiente. Esto es esencial para tomar decisiones informadas en la gestión de riesgos geológicos y proteger vidas y propiedades en áreas propensas a deslizamientos.
SELECCIÓN DEL MODELO
Existen diversos tipos de modelos de machine learning que se pueden utilizar, como algoritmos de regresión, árboles de decisión, redes neuronales, Máquinas de Vectores de Soporte (SVMs), entre otros. La elección del modelo depende de la naturaleza de los datos y del tipo de problema que se esté abordando. Ejemplos que ilustran la selección del modelo de machine learning.
Ejemplo 1: Predicción de la magnitud de terremotos:
Supongamos que estás trabajando en la predicción de la magnitud de terremotos en una región específica. Tu conjunto de datos contiene información histórica sobre terremotos, incluyendo la profundidad, la ubicación y la actividad sísmica previa. Para este tipo de problema de regresión, podrías considerar usar modelos como:
• Regresión Lineal: Este modelo podría ser una buena elección inicial si deseas establecer una relación lineal entre las características y la magnitud de los terremotos.
• Árboles de Decisión: Los árboles de decisión son adecuados para problemas de regresión y pueden capturar relaciones no lineales entre las características y la magnitud del terremoto.
• Redes Neuronales: Las redes neuronales pueden manejar problemas de regresión complejos y aprender representaciones profundas de los datos, lo que podría ser beneficioso si hay patrones no lineales importantes en los datos.
La elección del modelo dependerá de la complejidad de los datos y de la capacidad de generalización del modelo.
Ejemplo 2: Deteccion de fallas geologicas:
Supongamos que estás interesado en detectar la presencia de fallas geológicas en una región a partir de datos geofísicos y topográficos. Tu conjunto de datos contiene información sobre características geológicas y mediciones geofísicas. Para este problema de clasificación binaria (falla/no falla), podrías considerar modelos como:
• Máquinas de Vectores de Soporte (SVM): Las SVMs son eficaces en problemas de clasificación binaria y pueden ser útiles para separar eficazmente las regiones con fallas de las que no las tienen.
• Árboles de Decisión: Los árboles de decisión son interpretables y pueden ayudar a identificar las características más importantes para la detección de fallas geológicas.
• Random Forest: Un conjunto de árboles de decisión, como Random Forest, puede mejorar la precisión al combinar múltiples modelos.
DIVISIÓN DE DATOS
El conjunto de datos se divide en dos partes: una para entrenar el modelo y otra para evaluarlo. Esto permite evaluar la capacidad del modelo para generalizar patrones encontrados en datos nuevos.
• Conjunto de Entrenamiento: Esta parte se utiliza para enseñar al modelo cómo hacer predicciones. Puede representar, por ejemplo, el 80% de tus datos.
• Conjunto de Prueba: Esta parte se mantiene aparte y no se utiliza durante el entrenamiento. Se utiliza para evaluar qué tan bien el modelo puede hacer predicciones en datos nuevos y no vistos. Puede ser el 20% restante de tus datos.
La división de datos es fundamental para verificar si el modelo puede generalizar patrones encontrados en los datos de entrenamiento a datos nuevos y desconocidos.
ENTRENAMIENTO DEL MODELO
Se utiliza la parte de datos de entrenamiento para ajustar los parámetros del modelo. Durante este proceso, el modelo aprende a reconocer patrones y relaciones entre las de características y los resultados deseados, que en este caso serían los riesgos geológicos.
Durante el entrenamiento, el modelo ajusta sus parámetros para aprender a reconocer patrones y relaciones en los datos. Por ejemplo, el modelo puede aprender que áreas con alta inclinación y precipitación histórica son propensas a deslizamientos de tierra. Una vez que el modelo ha sido entrenado, puede hacer predicciones basadas en nuevas entradas de datos. Por ejemplo, si le proporcionas información sobre la inclinación y la precipitación actual en una ubicación específica, el modelo puede predecir la probabilidad de que ocurra un deslizamiento de tierra en ese lugar.
VALIDACIÓN Y AJUSTE FINO
Después del entrenamiento, se evalúa el modelo utilizando datos de validación para asegurarse de que esté funcionando correctamente. Si es necesario, se ajustan los parámetros del modelo para mejorar su rendimiento. Después de entrenar un modelo de Machine Learning, tienes un conjunto de datos de validación para evaluar su rendimiento antes de usarlo en la vida real.
• Conjunto de Validación: Utilizas un conjunto de datos separado, que no se ha utilizado durante el entrenamiento ni durante la división de datos previa. Este conjunto contiene información sobre terremotos recientes y sus características geofísicas y geológicas.
• Evaluación Inicial: Aplicas el modelo entrenado al conjunto de validación y evalúas su rendimiento utilizando métricas como la precisión, el recall y el F1-score. Descubres que el modelo tiene un alto número de falsos positivos (predicciones de terremotos que no ocurrieron) y deseas mejorarlo.
• Ajuste Fino: Para mejorar el rendimiento del modelo, decides ajustar los hiperparámetros. Por ejemplo, puedes modificar la profundidad máxima de un árbol de decisión o cambiar el valor de regularización en una máquina de vectores de soporte (SVM).
• Validación Continua: Después de realizar los ajustes, vuelves a evaluar el modelo en el conjunto de validación. Esta vez, notas una mejora en las métricas de rendimiento, con menos falsos positivos y una precisión general mejor.
• Optimización Iterativa: Si es necesario, continúas iterando en el proceso de ajuste fino, probando diferentes configuraciones de hiperparámetros y técnicas de regularización hasta que estés satisfecho con el rendimiento del modelo en el conjunto de validación
El proceso de validación y ajuste fino es esencial para garantizar que el modelo sea preciso y confiable antes de aplicarlo en situaciones del mundo real. Ayuda a identificar y corregir posibles problemas y a mejorar la capacidad del modelo para predecir riesgos geológicos de manera efectiva.
PREDICCIONES Y EVALUACIÓN
Una vez que el modelo está entrenado y validado, se puede utilizar para hacer predicciones sobre datos nuevos o no vistos. La calidad de las predicciones se evalúa al comparar los resultados del modelo con eventos reales que ocurrieron.
Luego de entrenar y ajustar el modelo, es hora de usarlo para hacer predicciones y evaluar su calidad.
• Predicciones: Utilizas el modelo entrenado para hacer predicciones sobre áreas específicas de la región. Por ejemplo, proporcionas información sobre la inclinación del terreno, la precipitación reciente y la cobertura vegetal en una ubicación en particular.
• Evaluación de Predicciones: Durante un período de tiempo, registras si ocurrieron o no deslizamientos de tierra en las áreas para las cuales hiciste predicciones. Luego, comparas las predicciones de tu modelo con la realidad.
• Métricas de Evaluación: Calculas métricas de evaluación, como la precisión, el recall y la F1-score, para medir qué tan bien el modelo predijo los deslizamientos de tierra en comparación con lo que realmente sucedió.
• Resultados: Descubres que el modelo tiene una alta precisión en la predicción de deslizamientos de tierra y un bajo número de falsos positivos. Esto significa que el modelo es efectivo para identificar las áreas en riesgo de deslizamientos.
• Aplicación en el Mundo Real: Con la confianza en las predicciones del modelo, puedes utilizarlo para emitir alertas tempranas y tomar medidas preventivas en áreas con alto riesgo de deslizamientos de tierra, lo que contribuye a la seguridad de la población.
Este proceso de predicciones y evaluación es esencial para verificar la eficacia del modelo en situaciones del mundo real y garantizar que esté cumpliendo su objetivo de predecir riesgos geológicos de manera precisa y útil.
ITERACIÓN Y MEJORA
Los modelos de machine learning pueden mejorarse continuamente. Se pueden incorporar nuevos datos y ajustar los modelos a medida que se recopila más información y se obtiene un mejor entendimiento de los factores que influyen en los riesgos geológicos.
Supongamos que estás trabajando en la predicción de erupciones volcánicas. Inicialmente, desarrollas un modelo basado en datos limitados. A medida que recopilas más datos y ganas un mejor entendimiento de los factores que influyen en las erupciones volcánicas, iteras el modelo, lo ajustas y lo mejoras continuamente. Esto se traduce en un modelo más preciso y confiable con el tiempo, lo que te permite emitir alertas tempranas y tomar medidas preventivas más efectivas para proteger a las comunidades cercanas a los volcanes. La mejora continua es esencial en la predicción de riesgos geológicos.
APLICACIÓN Y TOMA DE DECISIONES
Después de demostrar su eficacia en la predicción de riesgos geológicos, los resultados del modelo pueden utilizarse por entidades gubernamentales, instituciones de investigación y otros actores involucrados en la gestión de desastres para tomar decisiones informadas y planificar estrategias de mitigación.
• Aplicación en la Toma de Decisiones: Las autoridades gubernamentales y las agencias de gestión de desastres adoptan el modelo como parte de su sistema de alerta temprana. El modelo se ejecuta continuamente, tomando datos en tiempo real sobre la inclinación del terreno, la precipitación y otras variables relevantes.
• Alertas y Planificación de Evacuaciones: Cuando el modelo detecta un alto riesgo de deslizamiento de tierra en una ubicación específica, emite una alerta automática a las comunidades cercanas. Esto permite una evacuación oportuna y la implementación de medidas de seguridad.
• Planificación de Infraestructura: Con los resultados del modelo, las autoridades pueden tomar decisiones informadas sobre la planificación de la infraestructura. Por ejemplo, evitan la construcción de viviendas en áreas de alto riesgo y refuerzan la infraestructura crítica en esas zonas.
• Educación y Concienciación Pública: Utilizan los resultados del modelo para educar al público sobre los riesgos geológicos y cómo prepararse para ellos. Esto incluye la difusión de información sobre refugios temporales y kits de emergencia.
• Reducción de Pérdidas Humanas y Materiales: La aplicación del modelo ayuda a reducir significativamente las pérdidas humanas y materiales asociadas con los deslizamientos de tierra. Las comunidades están mejor preparadas y pueden tomar medidas preventivas.
Es importante tener en cuenta que la predicción de riesgos geológicos es un campo complejo y desafiante. Los modelos de machine learning pueden ser herramientas poderosas, pero deben utilizarse junto con el conocimiento y la experiencia de los geólogos y expertos en desastres para tomar decisiones efectivas y precisas.
En el siguiente video un ejemple de algoritmos de machine learning para la estimación de amenaza sísmica:
CONCLUSIONES
La predicción de riesgos geológicos mediante modelos de Machine Learning representa un avance significativo en la seguridad pública y la gestión de desastres naturales. A medida que la tecnología continúa evolucionando y la recopilación de datos mejora, podemos esperar que estos modelos sean aún más precisos y efectivos en la protección de nuestras comunidades frente a los riesgos geológicos. La colaboración entre científicos de datos, geólogos y organismos gubernamentales es esencial para aprovechar todo el potencial de esta emocionante área de investigación.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis