
Predicción de precios de minerales: análisis de datos y series temporales
INTRODUCCIÓN
¿Por qué buscamos predecir los precios de los minerales? Es importante porque genera interés en los inversionistas para realizar estrategias económicas y obtener ganancias, lo que a su vez puede permitir a empresas mineras junior que cotizan con commodities de su interés tengan oportunidad de financiamiento.
Principalmente el mercado de metales es uno de lo más volátiles y complejo en la predicción de su valor dentro de la bolsa. Sin embargo, debido a sus altas ganancias se hace muy competitivo para los inversionistas más aventurados. Por ello, en este artículo vamos a dar un ejemplo de modelo de trabajo y técnicas que podemos aplicar, por ejemplo, usar algoritmos de aprendizaje automático como el basado en un árbol de decisión.
Para introducirnos al flujo de trabajo y describir qué técnicas y modelos sean los más adecuados en predecir los precios, debemos tener presente las variables que harán fluctuante el análisis de los precios de minerales. Por ejemplo, políticas de la empresa así como de la región o país, economía general, otros mercado de valores, inversores, precios de otros metales, entre otros.
A continuación, la siguiente figura muestra los pasos del descubrimiento de conocimiento en base de datos ("Knowledge Discovery in Databases"):
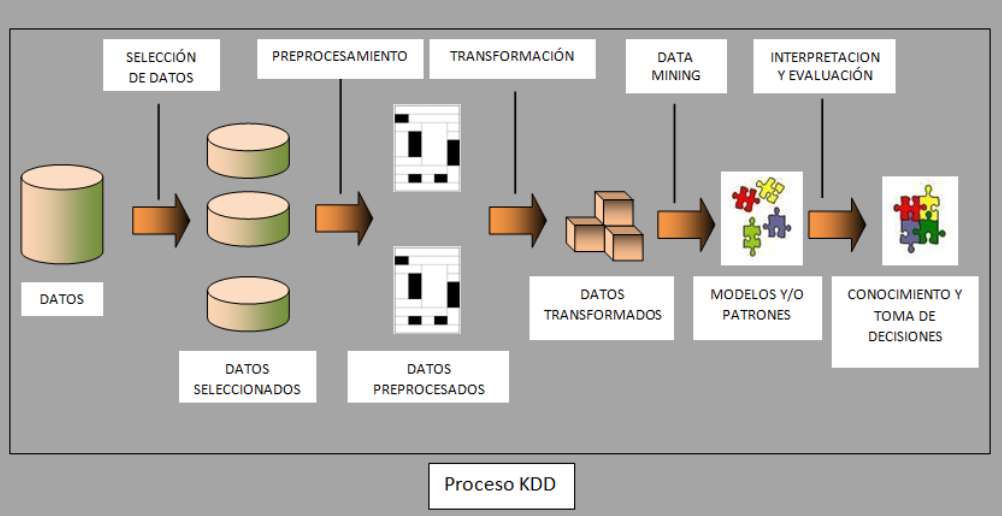
Figura 1. Proceso del "Knowledge Discovery in Databases" (KDD) (WebMining Consultores, 2011).
1. Selección de datos
Se determina las fuentes y tipos de datos, seleccionando las muestras que se insertarán para el procesamiento. Al ser el primer paso, se debe tener mayor cuidado en seleccionar los datos, atributos o tablas. Veamos ejemplos prácticos.
Para un trabajo de predicción del cobre por el método del árbol de decisiones (Liu, C. et al., 2016) se calculó en base a los precios del petróleo crudo, el gas natural, el oro, la plata, el cerdo magro y el café, también se tomó el índice Dow Jones y los precios pasados del cobre como variables independientes. De esta manera, se usaron siete factores externos que afectan los precios del cobre para construir las variables independientes.
Se utiliza el índice de Dow Jones porque los precios de metales están muy relacionados con el comportamiento de la demanda y consumo de las industrias por lo que afecta el entorno económico de manera global.
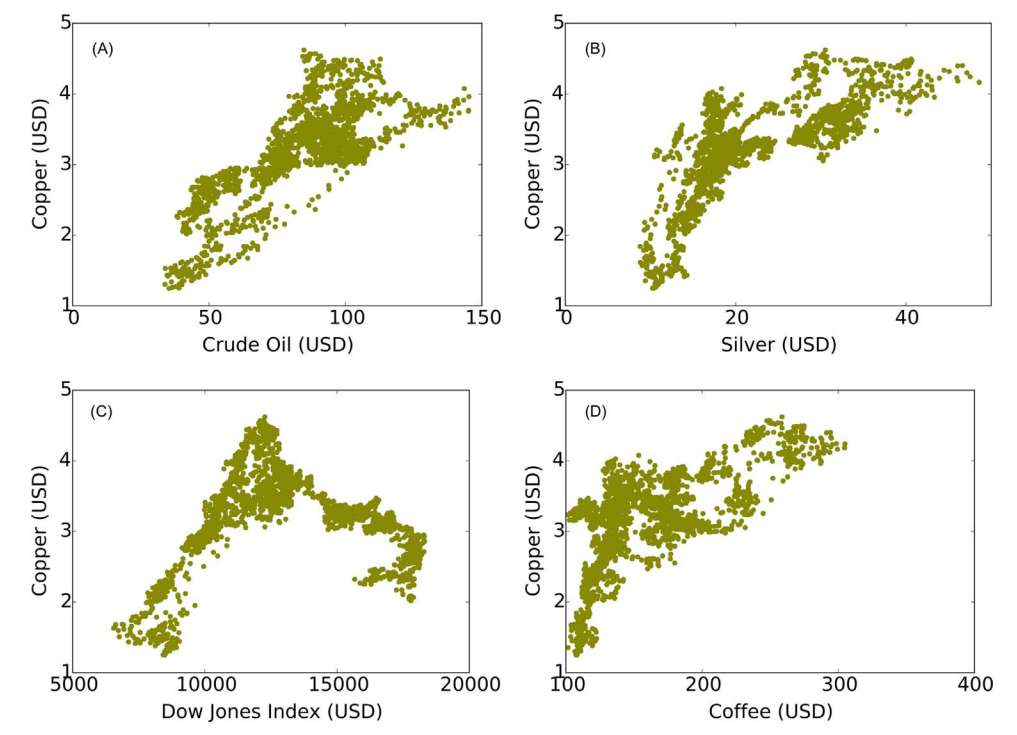
Figura 2. Correlación con cada una de las variables (los datos fueron obtenidos de los datos público de Investing.com, de 2008 a 2015).
Se determina las fuentes y tipos de datos, seleccionando las muestras que se insertarán para el procesamiento. Tener mayor cuidado al ser el primer paso para seleccionar datos, atributos o tablas. Veamos ejemplos prácticos.
En otro trabajo de predicción del oro se usó el método llamado "Whale Optimization Algorithm" (WOA) usando diez variables de entrada: tres tipos de cambio (rand sudafricano, rupia india y el yuan chino), dos tasas de inflación (de las economías más grandes: EE.UU. y China), precios del petróleo crudo y los precios pasados del cobre, plata, hierro y oro.
• El uso de tipos de cambio según un estudio de Chen et al. (2010) ha servido para pronosticar significativamente los precios de materias primas. Por ejemplo, la moneda sudafricana mostraba una relación estadística positiva con los metales como paladio y platino (Ciner, 2017).
2. Pre-Procesamiento:
Se realiza una limpieza de los datos, como eliminar los datos que sean inconsistentes, registros duplicados o información irrelevante.
• Para los casos que no se tenga datos de fechas como fines de semana o festivos (días que la bolsa no opera) se opta por promediar los calores de un día antes y después o podría eliminarse.
3. Análisis de correlación:
En esta sección es importante normalizar los múltiples índices financieros que a veces manejan varias escalas y dominios, es decir, homogenizar los datos.
Para hacer posible el cálculo podemos emplear los coeficientes de correlación cruzada de Pearson y así cuantificar las correlaciones cualitativas y medir el grado de dependencia lineal entre variables. Según Pearson (1895), un coeficiente de 1 es correlación positiva, 0 denota sin correlación y -1 es una correlación negativa.
Para lo cual usamos la siguiente ecuación:
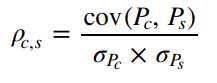
La multiplicación del divisor indica la desviación estándar de los precios del cobre y plata, respectivamente, y para la covarianza entre los precios se utiliza la siguiente ecuación matemática:
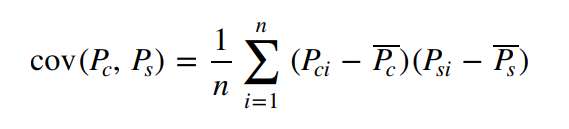
De nuestro primer ejemplo práctico, la correlación de sus siete variables para predecir el precio del cobre obtenemos la siguiente correlación:
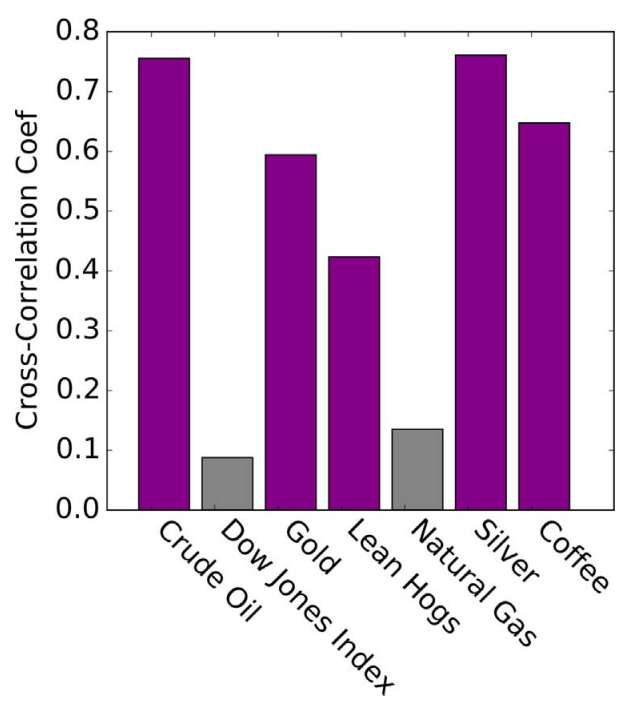
Figura 3. Correlación de Pearson entre el precio de cobre y sus variables.
Observamos que el precio de cobre tiene alta correlación con los precios del petróleo crudo, el oro y la plata. Por otro lado, el precio de cobre y el índice Dow Jones presentan poca correlación, esto puede explicarse porque el índice de Dow Jones abarca todos los sectores industriales y tal vez se recomendaría hacer más filtros.
• Para conseguir estos cálculos podemos usar el software SPSS.
4. Predicciones usando diferentes métodos:
Empecemos por revisar la literatura de algunos métodos eficientes para la predicción de metales. En un contexto reciente, varios estudios han optado por combinar los "pronósticos" debido a que diversifica el riesgo y da mejores resultados en la práctica. Según Timmermann (2006) la diversificación del riesgo es un principio importante en las finanzas para defender la agrupación de pronósticos.
El primer método es el aprendizaje del árbol de decisión.
Es un algoritmo de aprendizaje automático supervisado que funciona como un diagrama de flujo, dividiendo un conjunto de datos de entrenamiento para construir un modelo a través de procesos de partición recursivo entre nodos y ramas. El objetivo es maximizar la homogeneidad de los subconjuntos, lo que significa que las muestras dentro de cada subconjunto deben ser similares con respecto a la variable objetivo.
Para dividir los datos, este método usa criterios como la impureza de Gini (mide el grado de aleatoriedad), entropía (calcula la cantidad promedio de información necesaria para identificar la clase de un elemento) o la ganancia de información (cuantifica la reducción de entropía lograda por una división particular).
Entonces los parámetros en el modelo del árbol de decisión se seleccionan minimizando la impureza. Luego de entrenar el árbol con el conjunto de datos de entrenamiento, el modelo se puede utilizar para predecir el valor de una variable objetivo basado en las que son independientes. Para validar la predicción, se compara con datos pasados. Por ejemplo, en la figura 4, los precios previstos son los puntos rojos que se superponen muy bien a los valores reales que es la curva negra.
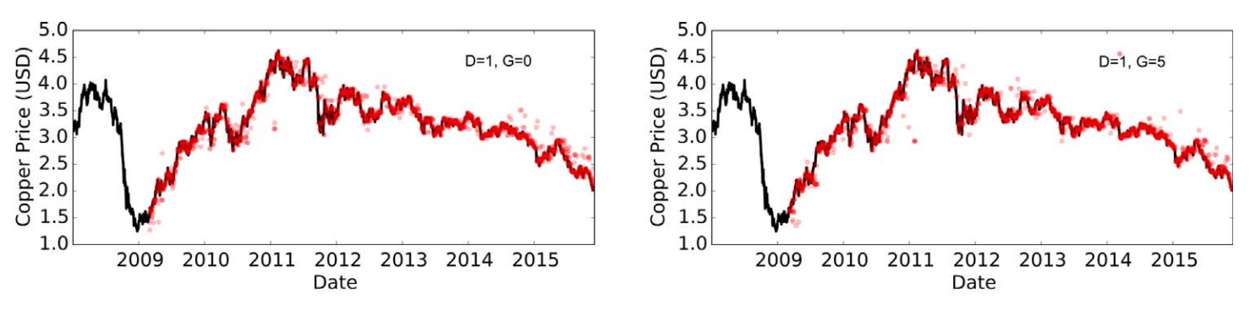
Figura 4. Ejemplo práctico del caso de predicción del cobre basado en el aprendizaje del árbol de decisión (donde D indica los días y G=0 indica el día demañana, G=1 para el de pasado mañana, y así continúa).
El segundo método son las redes neuronales de perceptrón multicapa (MLP).
Es un modelo matemático inteligente y no paramétrico que comprende un conjunto de elementos de procesamiento llamado "neuronas", justamente inspirada en el sistema nervioso biológico. Las neuronas en MLP consta de al menos tres capas de nodos: una capa de entrada, una capa oculta y una capa de salida. A excepción de los nodos de entrada, cada nodo es una neurona que utiliza una función de activación no lineal.

Figura 5. Arquitectura básica de una red neuronal MLP.
MLP utiliza una técnica de aprendizaje supervisado llamada retropropagación para el entrenamiento. El aprendizaje se produce en el perceptrón al cambiar los pesos de las conexiones después de procesar cada dato, en función de la cantidad de error en la salida en comparación con el resultado esperado. En este sentido, las conexiones entre neurona están representadas por los pesos que son los números reales ubicados en el intervalo [-1.11].
En MLP, cada neurona recibe información de una cierta cantidad de ubicaciones en la capa anterior. En la figura 5 podemos observar la arquitectura básica de este tipo de red neuronal, y la siguiente es una descripción matemática para cada capa en un MLP:
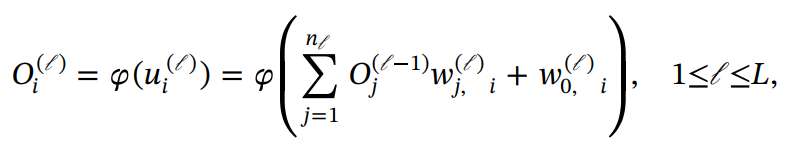
donde la función es una hiperbólica tangente no lineal para las capas intermedias, que también se reconocen como capas ocultas, y una función lineal para generar los resultados de la capa de salida.
Otro método es el algoritmo de optimización de ballenas (WOA).
Es un algoritmo reciente propuesto por Mirjalili y Lewis (2016), inspirado en el comportamiento social y de caza de las ballenas jorobadas (estrategia de caza con redes de burbujar). Las ballenas, en WOA, presentan una solución potencial al simular su movimiento en busca de presas:
1. La exploración del entorno al moverse aleatoriamente en el espacio de búsqueda para descubrir posibles soluciones.
2. La explotación ocurre con la ecolocalización para atacar la presa, lo que se traduce como converger a soluciones prometedoras.
3. El rodeo de las ballenas a su presa, se traduce como converger soluciones hacia un óptimo global.
El algoritmo WOA actualiza la posición de cada ballena en función de su posición actual, la posición de la mejor ballena y la distancia a la presa. En WOA, las redes de burbujas se simulan mediante un movimiento en espiral (ver la figura 6).
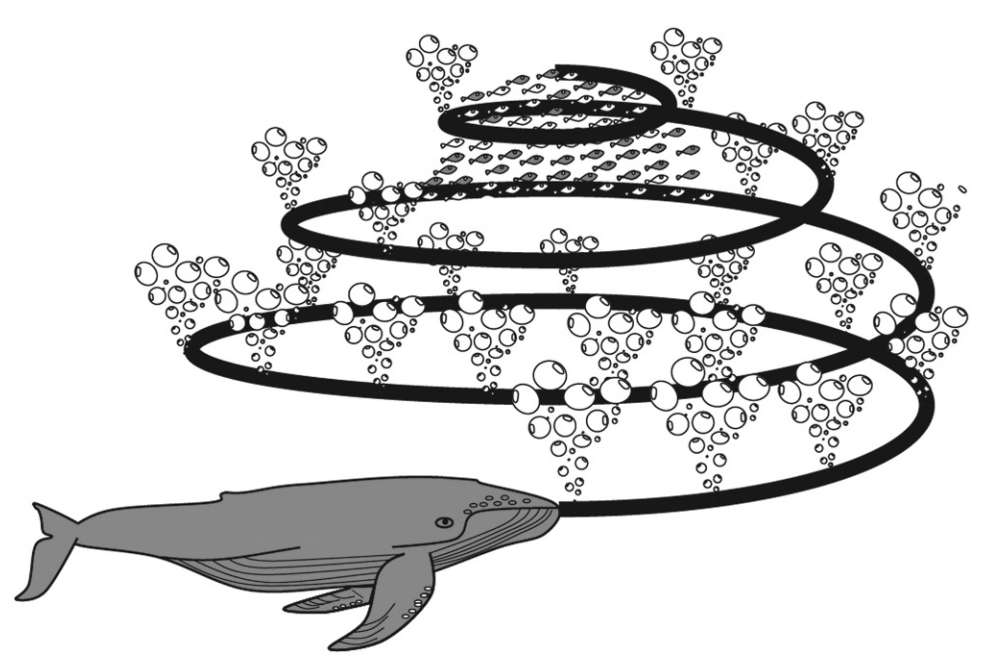
Figura 6. Comportamiento de alimentación de las ballenas jorobadas con redes de burbujas (Mirjalili y Lewis, 2016).
El algoritmo se diferencia de otros algoritmos porque mejora iterativamente las soluciones hasta que se logra la convergencia o se cumple un criterio de parada. Veamos una ecuación matemática que usa la posición de la ballena como X(t) y que se actuliza moviéndola en espiral alrededor de la presa como Xbest:
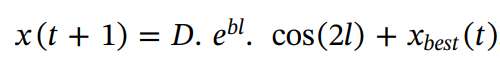
en este caso D = |x(t) - xbest(t)| es la distancia entre x(T) y xbest(t) en la iteración t, si l pertenece entre [-1,1] como número aleatorio, y b es una constante variable usada para definir la forma de espiral del algoritmo.
5. Análisis Estadísticos
Cuando se combina métodos y se quiere cuantificar los errores de predicción, se puede utilizar la prueba de suma de rangos de Wilcoxon, que consiste en determinar si existe una diferencia significativa entre los modelos o no en función del nivel significativo. Por ejemplo, en la comparación de los resultados del modelo WOA-NN (Alameer, et al. 2019) y el NN clásico presentan buenos resultados:
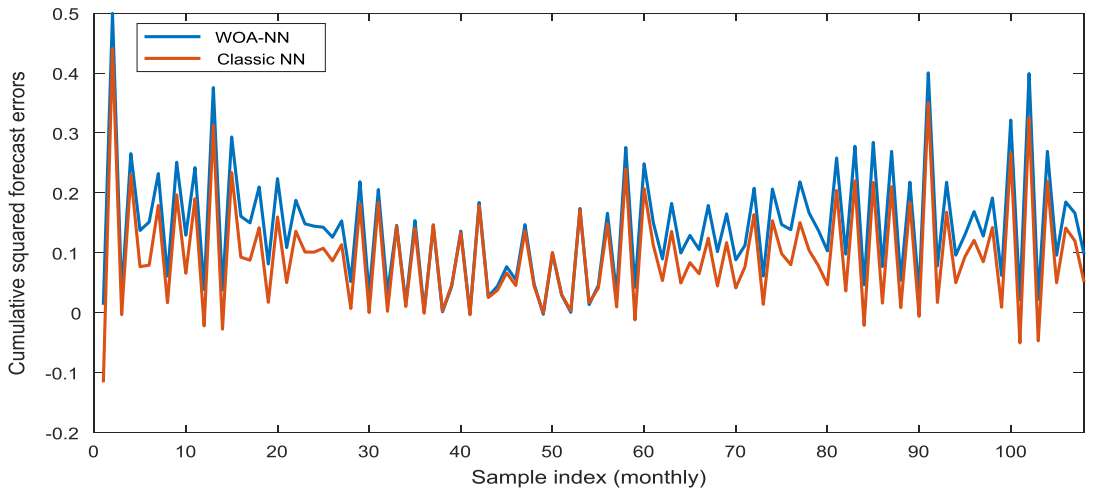
Figura 7. Resultados de la diferencia acumulada entre los errores de previsión al cuadrado del modelo ARIMA y el modelo WOA-NN.
CONCLUSIONES
• En una industria global consumidora de recursos como los metales, anticipar las variaciones de sus precios ayuda directa o indirectamente a las empresas y gobiernos en la toma de decisiones de inversión y estrategias financieras. Por lo que presentamos en el artículo algunos métodos que son aplicables a la predicción de metales, pero finalmente también puede extrapolarse a predecir costos en procesos como la molienda, refinación y otros costos de minería.
• Las ventajas en el algoritmo del árbol de decisión es que hace fácil su interpretación y el análisis de la relación entre los datos objetivos y, de entrada, y para identificar las variables independientes de mayor relevancia en la predicción de la variable objetivo. Y, adicionalmente, es posible usar utilizar variables categóricas (en lugar de numéricas) en nuestro enfoque basado en árboles de decisión. Por otro lado, el WOA-NN usado para entrenar la red neuronal MLP también mejora las precisiones de los pronósticos de metales. Según Alameer et al. (2019), cuando el WOA-NN se comparó con otros métodos (PSO-NN, GS-NN, GWO-NN y ARIMA) por medio de la prueba de suma de rangos de Wilcoxon (ver figura 7) se obtuvo un rendimiento superior.
• Finalmente, podemos reflexionar en la sensibilidad que tiene cada método al tener que interactuar con muchas variables y que mientras mayor sea el coeficiente de sus correlaciones podemos esperar resultados más confiables. Aun así queda abierta la mejora de la eficacia de estos de sistemas de predicción ya sea mediante la combinación de métodos o idear nuevos métodos.
BIBLIOGRAFÍA
• Alameer, Zakaria & Ewees, Ahmed & Elsayed Abd Elaziz, Mohamed & Ye, Hai. (2019). Forecasting gold price fluctuations using improved multilayer perceptron neural network and whale optimization algorithm. Resources Policy. 61. 250-260. 10.1016/j.resourpol.2019.02.014.
• Chen, Y.-C., Rogoff, K.S., Rossi, B., 2010. Can exchange rates forecast commodity prices? Q. J. Econ. 125, 1145–1194. 〈http://www.jstor.org/stable/27867508〉.
• Ciner, C., 2017. Predicting white metal prices by a commodity sensitive exchange rate. Int. Rev. Financ. Anal. 52, 309–315. https://doi.org/10.1016/j.irfa.2017.04.002.
• Gargano, A., Timmermann, A., 2014. Forecasting commodity price indexes using macroeconomic and financial predictors. Int. J. Forecast. 30 (3), 825–843.
• Liu, Chang & Hu, Zhenhua & Li, Yan & Liu, Shaojun. (2017). Forecasting copper prices by decision tree learning. Resources Policy. 52. 427-434. 10.1016/j.resourpol.2017.05.007.
• Mirjalili, S., Lewis, A., 2016. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008.WebMining Consultores. (2011). KDD: Proceso de Extracción de conocimiento. Obtenido de Blog: http://www.webmining.cl/2011/01/proceso-de-extraccion-de-conocimiento/.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis