
Machine Learning para la prevención de riesgos geológicos
Machine Learning para la prevención de riesgos geológicos
Huamán Chicoma Danfer Arián
Primer Bootcamp de Tecnología Aplicado a la Minería LATAM
CODEa UNI
Lima, Perú
Resumen: En este artículo se describe el funcionamiento de Machine Learning, un primer alcance y sus aplicaciones a ciencias de la tierra como lo es la Geología, nos centramos netamente en la prevención de riesgos geológicos y un ejemplo claro usado en centroamérica, describiendo los parámetros usados y la metodología descrita por el autor.
Abstract: This article describes the operation of Machine Learning, a first scope and its applications to earth sciences such as Geology, we clearly focus on the prevention of geological risks and a clear example used in Central America, describing the parameters used and the methodology described by the author.
MACHINE LEARNING:
Se podría describir como una rama o un subconjunto de la inteligencia artificial (IA) que permite que las máquinas aprendan del usuario o entorno sin ser expresamente programadas para un fin en específico. Una habilidad indispensable para hacer sistemas capaces de identificar patrones entre los datos para hacer predicciones. A modo de ejemplo podemos mencionar que esta tecnología está presente en las siguientes aplicaciones: recomendadiones de Netflix o Spotify en base a los gustos del usuario, las respuestas inteligentes de Gmail o el habla de Siri y Alexa.
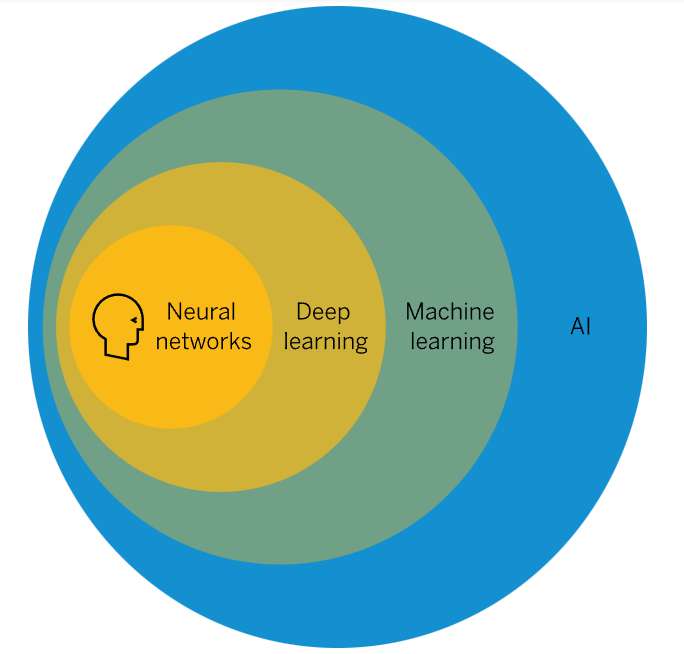
Fig. 1 Inteligencia artificial y sus componentes
1. ¿Cómo funciona el Machine Learning?
Se compone de diferentes tipos de modelos de machine learning, y utiliza varias técnicas algorítmicas, de manera general se puede describir de la siguiente manera:
• Recopilacion de datos: El proceso comienza con la recopilación de datos relevantes para la tarea que se desea resolver.
• Preprocesamiento de datos: Los datos recopilados a menudo requieren limpieza y transformación.
• Selección de características: En muchos casos, no todas las características o variables en los datos son relevantes para la tarea.
• División de datos: Los datos se dividen en conjuntos de entrenamiento y prueba.
• Entrenamiento del modelo: Durante la fase de entrenamiento, el algoritmo de machine learning utiliza el conjunto de entrenamiento para aprender patrones y relaciones en los datos.
• Validación y ajuste de hiperparámetros: Es común utilizar una parte del conjunto de entrenamiento para la validación y ajuste de hiperparámetros.
• Evaluación del modelo: Una vez entrenado y validado, el modelo se evalúa utilizando el conjunto de prueba.
• Predicción o clasificación: Después de entrenar y evaluar el modelo, se puede utilizar para hacer predicciones o clasificar nuevos datos sin etiquetas.
• Optimización y ajuste: Si el modelo no cumple con los criterios de rendimiento deseados, es posible que se realicen ajustes en la selección de características.
• Despliegue en producción: Una vez que se obtiene un modelo satisfactorio, se puede implementar en un entorno de producción para su uso en aplicaciones del mundo real.
2. Aprendisaje supervisado
En los algoritmos de aprendizaje supervisado, a la máquina se le enseña mediante ejemplos. Los modelos de aprendizaje supervisados consisten en pares de datos de "entrada" y "salida", donde la salida se etiqueta con el valor deseado.
3. Aprendisaje no supervisado
En los modelos de aprendizaje no supervisado, no existe una clave de respuesta. La máquina estudia los datos de entrada –muchos de los cuales no están etiquetados ni estructurados– y comienza a identificar patrones y correlaciones, utilizando todos los datos relevantes y accesibles. En muchos sentidos, el aprendizaje no supervisado sigue el modelo de cómo los humanos observan el mundo. Utilizamos la intuición y la experiencia para agrupar cosas.
4. Aprendisaje semisupervisado
En un mundo perfecto, todos los datos se estructurarían y etiquetarían antes de ser introducidos en un sistema. Pero como es obvio que esto no es factible, el aprendizaje semisupervisado se convierte en una solución viable cuando hay grandes cantidades de datos crudos y no estructurados. Este modelo consiste en introducir pequeñas cantidades de datos etiquetados para aumentar los data sets sin etiquetar.
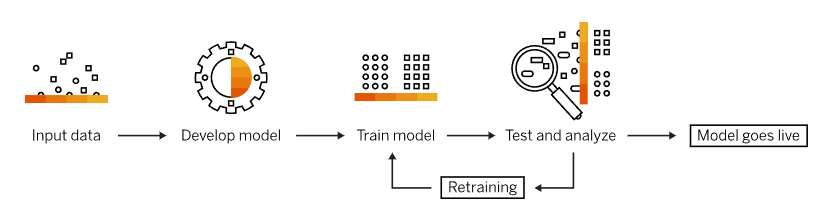
Fig. 2 Funcionamiento del proceso de Machine Learning
ML CON APLICACIONES A GEOLOGÍA:
Como se ha descrito Machine Learning es una herramienta que a través de algoritmos informáticos mejoran automáticamente la experiencia para generar resultados predictivos de forma masiva, la dificultad radica en querer llevar esta herramienta al campo de las ciencias de la tierra, en este caso de la geología, debido a que existen un sin número de variables de dificil predicción y monitoreo, ante ello, investigadores de la Universidad de Valencia en colaboración con la Universidad de Oxford y el Instituto Max Planck de Biogeoquímica, plantean modelos muy flexibles y eficaces para la estimación de variables de interés a partir de datos y observaciones, que ayudan a tener una mejor interpretación de la geología de cada país.
En pocas palabras lo que se desea lograr es que se introduzca la data y que el Machine Learning logre predecir (lugares de interés geológico, minero, hidrocarburos, entre otros), para ser codificado y generar un programa, con el cual se obtiene una nueva data, que, posteriormente se somete a pruebas de funcionamiento y así conseguir el resultado o la predicción del problema planteado.
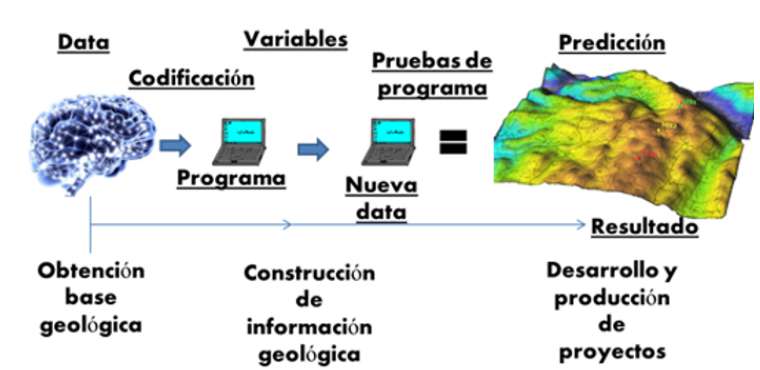
Fig. 3 Esquema general de funcionamiento del Machine Learning - Andrés Alvarez 2021
Un claro ejemplo de la aplicación del Machine Learning en geología, específicamente en la parte minera, son los depósitos de oro alojados en el supergrupo Birimian y el Grupo Tarkwaian en Ghana, para este análisis se contempló las siguientes variables: un área aproximada de 68,000km2, 350 datos de minerales conocidos, geofísica aeroportada, geología regional y local, y el ranking de mineralizaciones de acuerdo al tamaño.Todo esto, sumado al modelo geológico de la zona, permitió obtener el mapa predictivo, a través del cual se generaron las anomalías del mineral de interés, en este caso, de oro:
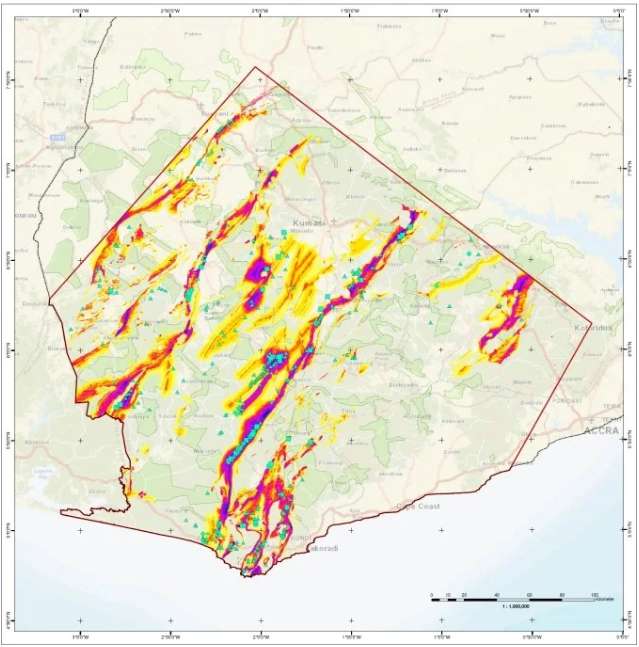
Fig. 4 Mapa predictivo para el Oro.
¿Cuales son los beneficios de haber aplicado esta tecnología?
• Fácil de leer
• Suficientemente preciso (100 m)
• Incluye conocimiento existente
• Actualizable
• Útil para planeamiento nacional/regional
• Útil para planes de ordenamiento territorial
PREVENCIÓN DE RIESGOS GEOLÓGICOS
Se describirá el como se uso Machine Learning para un caso de prevención de riesgo en centroamérica:
APLICACIÓN DE MACHINE LEARNING AL ANÁLISIS DE CONTAMINANTES EN ACUÍFEROS
a. Objetivos:
• Validar el empleo de la tecnología DInSAR (Interferometría Diferencial con Radar de Apertura Sintética) para la prevención de riesgos geológicos en infraestructuras prioritarias de Centroamérica.
• Dicho análisis consistirá en estimar la incertidumbre de las series de velocidades DInSAR y de la velocidad calculada por esta técnica.
• Integrar la técnica DInSAR en un sistema de monitoreo regional que permita reducir la incertidumbre en la prevención de riesgos ligados a la tectónica de placas.
b. Area de estudio:
El área de estudio seleccionada es la Región Centroamericana. Es un área que, por su tectónica y la cantidad de estructuras sísmicas además del gran vacío de datos que existe, la convierten en una zona de especial interés para el estudio.
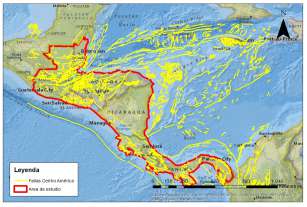
Fig. 5 Ubicación de la zona de estudio
c. Metodología:
Fase Modelización sísmica:
El primero de los pasos corresponde a la actividad de investigación sismológica que parte a su vez de las campañas de campo; esta fase consiste en la adquisición de datos mediante diferentes campañas batimetría, campañas GPS, altimetria, etc.. El subproyecto 2 dará inició a la producción de los mapas de riesgo de las zonas de estudio: las grandes ciudades de las ciudades centro americanas. La modelización de los escenarios sísmicos toma como base el empleo combinado de herramientas SIG, Hojas de cálculo e interpretación experta de los resultados.
Fase DInSAR
En esta segunda fase se emplea la tecnología DInSAR para validar los datos resultantes de la fase anterior. Se proponen las siguientes actividades:
1) Integración de los datos de auscultación disponibles, especialmente campañas GPS/GNSS, en una base de datos del proyecto.
2) Armonización y depurado de las series de datos GPS/GNSS.
3) Obtención del catálogo de imágenes SAR correspondiente a las series de datos disponibles empleando sensores actuales
4) Procesado DInSAR de las imágenes SAR empleando la tecnología desarrollada por Detektia.
5) Validación de velocidades de deformacion observadas por técnica DInSAR con la base de datos de ascultación.
6) Estimación de la incertidumbre de las series de velocidades.
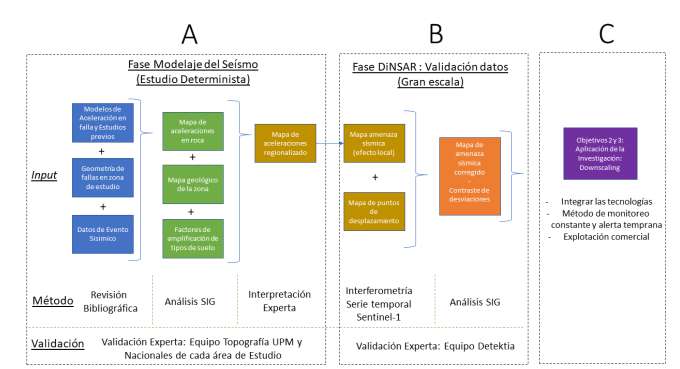
Fig. 6 Metodología
d. Resultados:
El primer producto que se conseguiría empleando el método descrito, sería un mapa de peligrosidad contrastado. Ello lo podemos evidenciar en la Fig. 7, se pueden ver los desplazamientos en la dirección de mira del satélite (geometría ascendente) de San José para el periodo 2015 y 2021. El resultado final será la relación entre este mapa de velocidades y el mapa de aceleraciones.
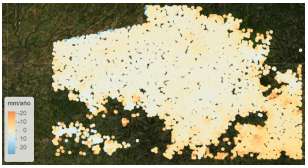
Fig. 7 Ejemplo de desplazamiento en San José
Otro contexto de apliacion es el siguiente: se puede observar una carretera en Colombia en una zona montañosa en la que se detectan movimientos de hasta 13 milímetros/año. La monitarización en tiempo real puede ser posible combinando los resultados obtenidos por DInSAR con Inteligencia artificial, considerando variables como la precipitación, la temperatura, topografía, etc.
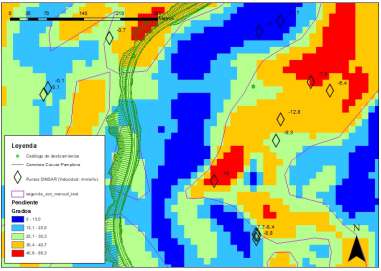
Fig. 8 Análisis multivariable preliminar para carretera en Colombia
CONCLUSIONES:
• Existe un impacto de la tecnología también desde la perspectiva social. El riesgo de desastre debido a causas naturales o tecnológicas puede minimizarse gracias al desarrollo de soluciones tecnológicas de vigilancia. En todo caso, lo que conseguimos con el estudio de cambios a nivel milimétrico es reducir la vulnerabilidad como determinante del colapso de infraestructuras.
• La interferometría diferencial de radar de apertura sintetica (DInSAR) es una técnica de teledetección que garantiza la calidad de su empleo en la ingeniería civil (García-Sánchez 2019; Cigna and Tapete 2021).
• La presente propuesta responde al reto de desarrollar herramientas que permitan prevenir y reducir los riesgos que amenazan el desarrollo en países de Centroamérica, que a posterior se puede extender añadiendo o quitando parámetros.
• Como se ha descrito, la monitorización de infraestructuras empleando tecnología radar satelital supone ahorros sustanciales, tanto gastos de personal que tienen que desplazarse hacia las infraestructuras para realizar las mediciones, como los ahorros en costes inherentes del mantenimiento preventivo.
REFERENCIAS:
• ABRAHAMSON, N.A., SILVA, W.J., and KAMAI, R., 2013. Update of the AS08 Ground-Motion Prediction Equation Based on the NGA-West2 Data Set, Pacific Earthquake Engineering Research Center University of California, Berkeley, PEER 2013/04
• A review of the Birimian Supergroup- and Tarkwaian Group-hosted gold deposits of Ghana. Smith, A, Henry, G y Killian, S. 2, Auckland Park : IUGS, 2016, Vol. 39.
• BAKON, M., I. OLIVEIRA, D. PERISSIN, J. J. SOUSA, and PAPCO, J., 2017. A Data Mining Approach for Multivariate Outlier Detection in Postprocessing of Multitemporal InSAR Results. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 10(6), pp. 2791-2798. DOI: 10.1109/JSTARS.2017.2686646
• BBVA. BBVA. 'Machine learning': ¿qué es y cómo funciona? [En línea] 08 de Noviembre de 2019
• DETEKTIA. 2021. Tecnología InSAR. Detectamos desde el espacio desplazamientos milimétricos de la superficie terrestre. Available: https://detektia.com/ [7/23, 2021].
• EZQUERRO, P., HERRERA, G., MARCHAMALO, M., TOMÁS, R., BEJARPIZARRO, M., MARTÍNEZ, and MARÍN, R., 2014. A quasielastic aquifer deformational behavior: Madrid aquifer case study. Journal of Hydrology, 519(2014), pp. 1192–1204.
• EZQUERRO, P., HERRERA, G., MARCHAMALO, M., TOMÁS, R., BEJARPIZARRO, M., MARTÍNEZ, and MARÍN, R., 2014. A quasielastic aquifer deformational behavior: Madrid aquifer case study. Journal of Hydrology, 519(2014), pp. 1192–1204.
• Mitchell, Tom. Machine Learning. s.l. : McGraw-Hill, 1997.
• Mining BIG Data: the Future of Exploration Targeting Using Machine Learning. Desharnais, G, y otros, y otros. Blainville Québec : SGS Canada Ltd. Geological Services, 2017.
• Pizano, L. Machine Learning aplicado a la geología. Lima : INGEMET, 2021.
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis