
Aprendizaje por Transferencia, Redes Neuronales Convolucionales aplicados al Análisis de Emociones a Través de Imágenes
1. RESUMEN
Este artículo presenta un análisis detallado sobre cómo las redes neuronales convolucionales (CNNs) y el aprendizaje por transferencia pueden ser herramientas fundamentales en la detección y predicción de emociones humanas, como la alegría, tristeza, enojo y miedo. Además, se describe las cómo redes neuronales entrenadas anteriormente tales como InceptionV3 pueden ser usados en la mejora de la precisión del modelo. La red neuronal más destacada, es una versión adaptada de InceptionV3, demostró rendimiento superior comparado con las otras tres arquitecturas de Red Neuronal. Las imágenes ingresadas a cada una de las Redes Neuronales tienen un tamaño de entrada de 150x150, para las dos primeras redes neuronales las imágenes ingresan en un solo canal de color (grayscale), mientras que para las dos últimas las imágenes ingresan con tres canales de colores (rgb), La red neuronal con mayor rendimiento alcanzó un accuracy de entrenamiento del 99.60%, validación del 67%, y un accuracy de 65% en el conjunto de testeo, mientras que la red neuronal con menor rendimiento alcanzó un accuracy de entrenamiento del 0.34%, validación del 0.31%, y un accuracy del 0.30% en el conjunto de testeo, Cada una de las redes neuronales construidas presentan diversas particularidades tales como situaciones de overfitting y underfitting.
2. INTRODUCCIÓN
La capacidad de las máquinas para comprender y predecir emociones humanas a través del análisis de imágenes es un campo en constante desarrollo. Las redes neuronales convolucionales (CNNs) han demostrado ser una técnica poderosa para extraer características visuales y patrones únicos de las imágenes. Sin embargo, es esencial comprender la arquitectura adecuada y las técnicas para abordar los desafíos comunes en el entrenamiento y la generalización de estos modelos.
2.1 REDES NEURONALES CONVOLUCIONALES
Las redes neuronales convolucionales son un tipo de arquitectura de aprendizaje profundo diseñada específicamente para el análisis de datos visuales, como imágenes. A diferencia de las redes neuronales tradicionales, las CNNs incorporan capas convolucionales y de pooling para detectar patrones locales en las imágenes. Estas capas imitan la forma en que el cerebro humano procesa información visual, permitiendo que la red aprenda características relevantes, como bordes, texturas, formas y otros.
2.2 INCEPTIONV3
InceptionV3, al ser una arquitectura de red neuronal convolucional (CNN), está diseñada para tareas de clasificación de imágenes. Ha sido entrenado en un gran conjunto de datos que contiene una amplia variedad de imágenes de diferentes categorías. El conjunto de datos en el que a menudo se entrenó previamente es el conjunto de datos ImageNet, que incluye más de un millón de imágenes de miles de clases.
El conjunto de datos de ImageNet cubre una amplia gama de objetos, animales, escenas y más. Algunos ejemplos de categorías que pueden estar presentes en el conjunto de datos de ImageNet y, por extensión, en los datos de entrenamiento del modelo InceptionV3 incluyen:
- Animales: Gatos, perros, pájaros, caballos, elefantes, etc.
- Objetos: Coches, sillas, mesas, aviones, bicicletas, etc.
- Naturaleza: Playas, montañas, bosques, lagos, ríos, etc.
- Alimentación: Frutas, verduras, platos, postres, etc.
- Objetos cotidianos: Libros, portátiles, teléfonos, botellas, etc.
- Arquitectura: Edificios, puentes, monumentos, etc.
- Personas: rostros, poses corporales, actividades, etc.
Estas categorías son solo una pequeña representación de lo que podría estar presente en los datos de entrenamiento de InceptionV3. La idea detrás del entrenamiento en un conjunto de datos tan diverso es permitir que el modelo aprenda una amplia gama de características y patrones que pueden ayudar a hacer predicciones precisas en una amplia variedad de imágenes del mundo real.
2.3 APRENDIZAJE POR TRANSFERENCIA
El aprendizaje por transferencia es una técnica en la que un modelo pre entrenado en una tarea relacionada se adapta para resolver un problema específico. En el contexto de InceptionV3, esta técnica implica aprovechar el conocimiento adquirido en la clasificación de objetos en imágenes y aplicarlo al análisis de emociones. Al iniciar con pesos ya ajustados en las capas tempranas de la red, el modelo puede acelerar el proceso de entrenamiento y lograr una mejor generalización en nuevos datos.
3. DESARROLLO
En este estudio, se llevó a cabo una exploración de diferentes arquitecturas de redes neuronales convolucionales (CNNs) con el objetivo de analizar su capacidad para detectar y predecir emociones humanas presentes en imágenes. Se utilizó un conjunto de datos que contenía 1200 imágenes categorizadas en cuatro emociones distintas: alegría, tristeza, enojo y miedo. Cada categoría estaba compuesta por 300 imágenes, y se reservaron 200 imágenes aleatorias del total de 1200 para el conjunto de testeo.
Las siguientes arquitecturas de redes neuronales se evaluaron en este estudio:
3.1 RED NEURONAL SECUENCIAL TRADICIONAL
La primera arquitectura, una CNN secuencial logró un accuracy de entrenamiento del 52.26% y un accuracy de validación de 43%, indicando que el modelo estaba memorizando los datos de entrenamiento en lugar de aprender patrones generales. Esto se confirmó con un bajo accuracy de prueba del 34%, sugiriendo una incapacidad para generalizar a nuevas imágenes.
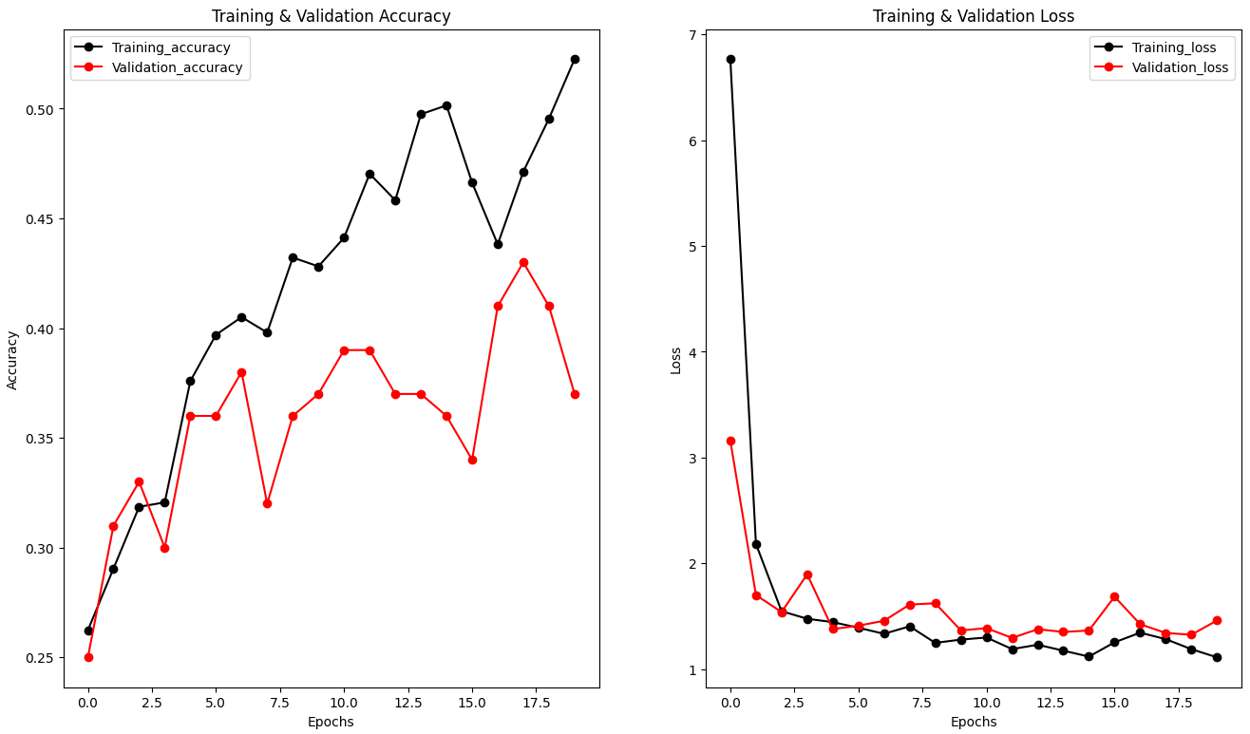
Fig.1 Epoch vs. Validation, Loss y Training
3.2 RED NEURONAL SECUENCIAL CON DROPOUT
En la segunda arquitectura, se implementaron capas de dropout. Sin embargo, a pesar de estos ajustes, el modelo no logró mejoras significativas en términos de precisión. A lo largo de 20 épocas de entrenamiento, el accuracy de validación se mantuvo entre 30 y 35%,, indicando que la red no podía aprender de manera efectiva ni generalizar patrones emocionales de las imágenes de entrenamiento.
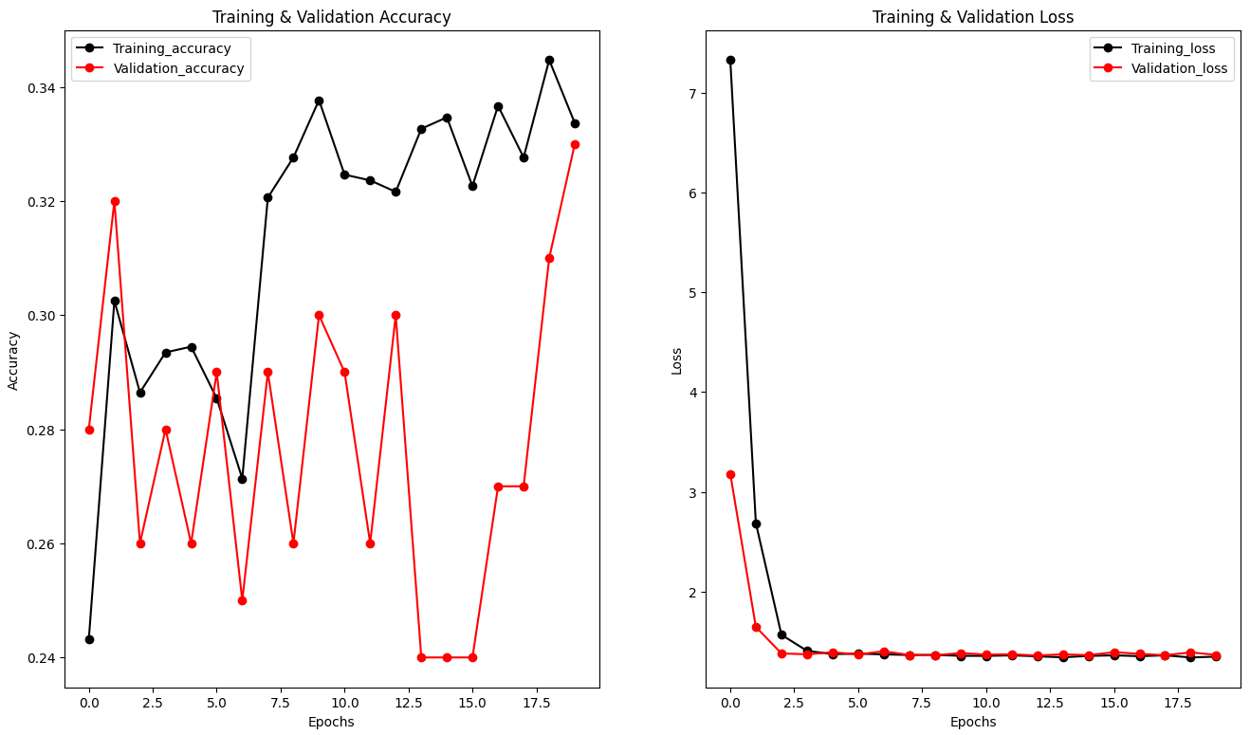
Fig.2 Epoch vs. Validation, Loss y Training
3.3 RED NEURONAL INTEGRADA CON INCEPTIONV3 Y DROPOUT
La tercera arquitectura se basó en la arquitectura InceptionV3, que aprovecha módulos de convolución de diferentes tamaños para capturar características a diferentes escalas. La técnica de transferencia de conocimiento se utilizó para adaptar el modelo a la tarea de análisis de emociones. A pesar de lograr un impresionante accuracy de entrenamiento del 97.89%, la arquitectura InceptionV3 demostró un patrón de overfitting persistente, con un accuracy de validación de 69% y un accuracy de prueba de 64.99%.
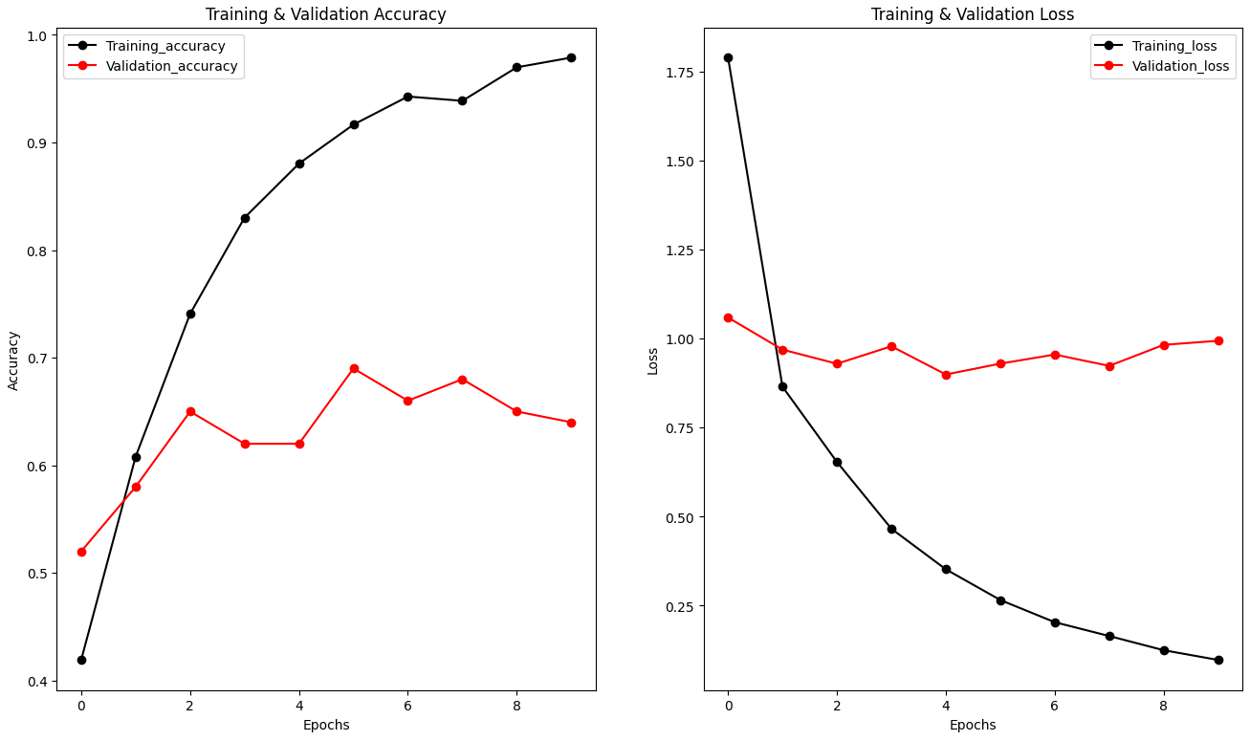
Fig.3 Epoch vs. Validation, Loss y Training
3.4 RED NEURONAL INTEGRADA CON INCEPTIONV3 Y SIN DROPOUT
La cuarta arquitectura eliminó las capas de dropout que se habían agregado previamente. Aunque esto resultó en un accuracy de entrenamiento aún mayor, llegando al 99.60%, el overfitting siguió siendo un problema evidente. El accuracy de validación alcanzó el 67%, y el accuracy de prueba fue del 65%, lo que demostró que el modelo todavía tenía dificultades para generalizar a nuevas imágenes.
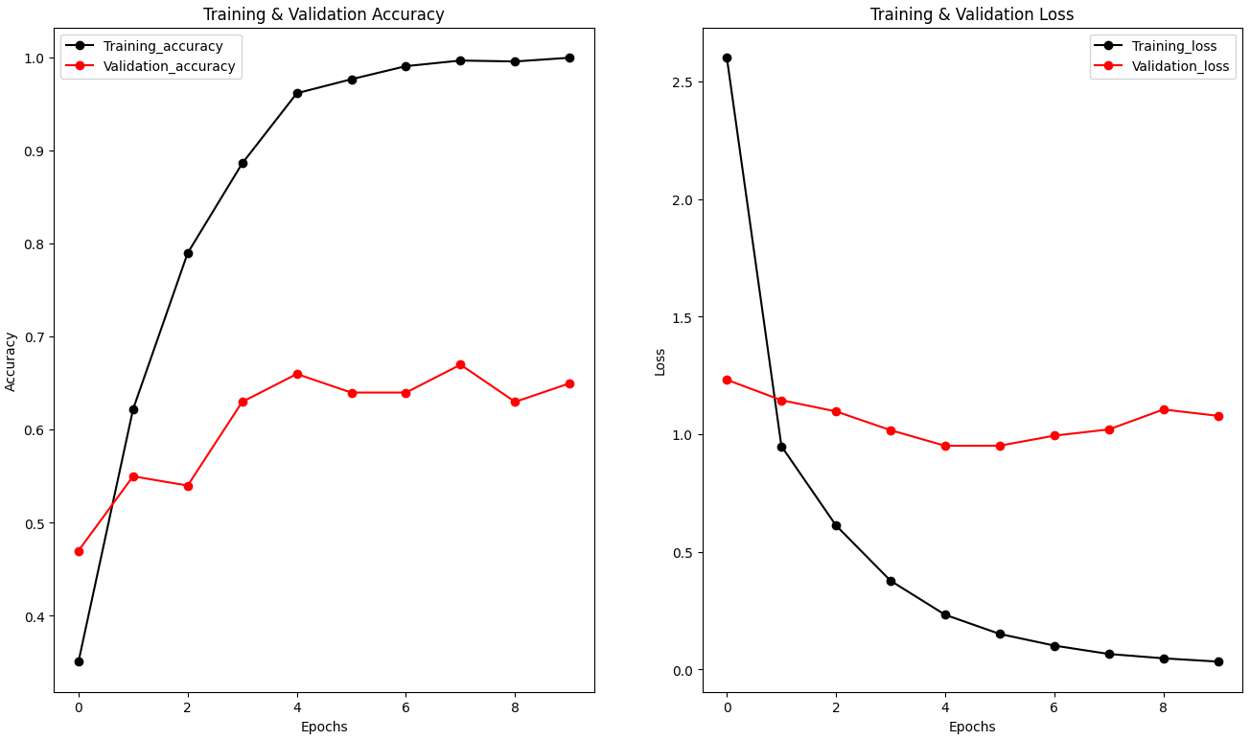
Fig.4 Epoch vs. Validation, Loss y Training
4. RESULTADOS Y DISCUSIÓN
El estudio involucró cuatro arquitecturas de CNNs para el análisis de emociones: una secuencial tradicional, una secuencial con capas de Dropout para abordar el underfitting, y dos últimas basadas en InceptionV3 una involucrando capas de Dropout, y una última sin capas de Dropout.
Los resultados ilustran claramente el delicado equilibrio entre overfitting y underfitting en el entrenamiento de modelos de CNNs. Las arquitecturas más complejas, como InceptionV3, demostraron la capacidad de aprender características relevantes, pero también fueron más susceptibles al overfitting. El uso de capas de dropout demostró ser no eficaz en este caso para mitigar el overfitting. Además, la aplicación del aprendizaje por transferencia demostró su valía al mejorar la capacidad del modelo para aprender de manera eficiente y generalizar a nuevas imágenes.
Los resultados indican que las arquitecturas basadas en InceptionV3 lograron mayores precisiones en el entrenamiento, pero enfrentaron problemas de overfitting en los conjuntos de validación y prueba.
5. CONCLUSIONES
La combinación de redes neuronales convolucionales y el aprendizaje por transferencia ofrece un enfoque prometedor para la detección de emociones en imágenes. La arquitectura InceptionV3 destaca por su capacidad para capturar características complejas, mejorando el rendimiento en tareas emocionales. Sin embargo, es esencial abordar los desafíos de overfitting y underfitting para lograr una interpretación precisa de las emociones humanas en diversas situaciones. La investigación continua en este campo puede conducir a avances significativos en la comprensión y predicción de las respuestas emocionales a través del análisis de imágenes.
Este estudio destaca la importancia de elegir y ajustar adecuadamente las arquitecturas de CNNs en función del conjunto de datos y los objetivos específicos. La utilización de InceptionV3 con aprendizaje por transferencia se presenta como una estrategia efectiva para mejorar el rendimiento del modelo en tareas emocionales. Sin embargo, persisten desafíos en la administración del overfitting y underfitting, lo que sugiere que es esencial continuar investigando para lograr un equilibrio óptimo en la precisión y la generalización. En última instancia, el análisis de emociones a través de imágenes con redes neuronales convolucionales y técnicas de aprendizaje por transferencia tiene el potencial de revolucionar nuestra comprensión de las respuestas emocionales humanas en diversas situaciones.
Anexos:
Desarollo y datos del entrenamiento en Tensorboard
- https://tensorboard.dev/experiment/SrfGlC6NRkWIxNFPNKRoCg/
Comentarios
Registrate o Inicia Sesión para comentar y obtener Cursos de pago gratis